Datavault
Dit document dient inzicht te geven in de datavault-GRIP modules en hoe je er een datavault-datawarehouse mee kan maken.
Dit document is bedoeld voor zowel de beheerder als de ontwikkelaar met verstand van datavault.
Het is niet het doel om datavault uit te leggen. De situatie van dit moment is dat de twee datavault-functies toereikend zijn om voor Schiphol de gewenste datavault-warehouses te kunnen realiseren. Mochten de routines te kort schieten dan moeten aanvullende modules ontwikkeld worden.
GRIP datavault
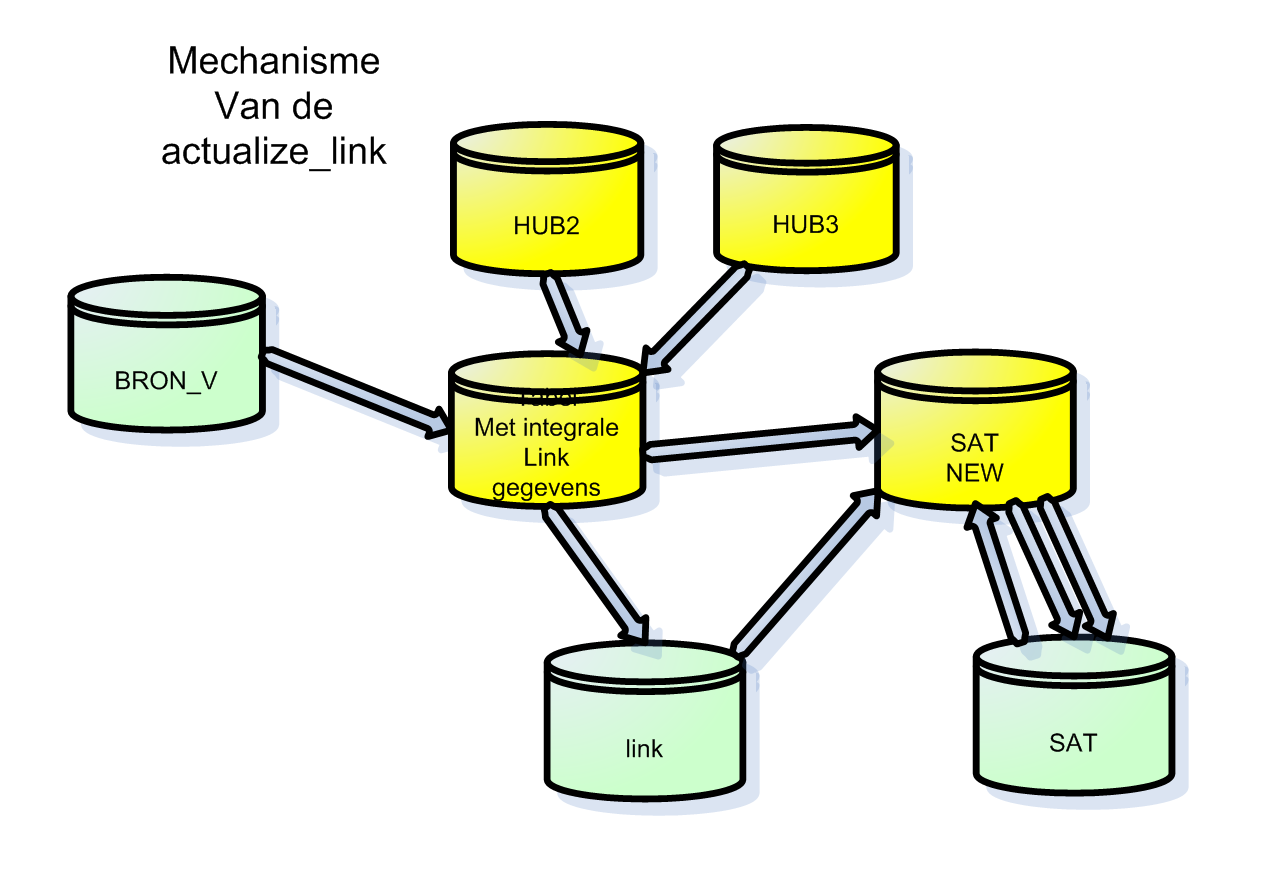
In het onderstaande plaatje zie je in lichtblauw de tabellen van de bron. Deze bron-tabellen worden op een bepaalde manier beschikbaar gesteld aan de datavaultroutines. Als eerste worden de Hubs(donderblauw) geladen, daarna de satelliet van de hub(geel). Tenslotte wordt de LINK geladen ( rood ) en vervolgens de sateliet van de link. Indien bij het toevoegen van een link een of meerdere hubs niet bestaan, worden de hubs vanuit de link-actualisatie aangemaakt.
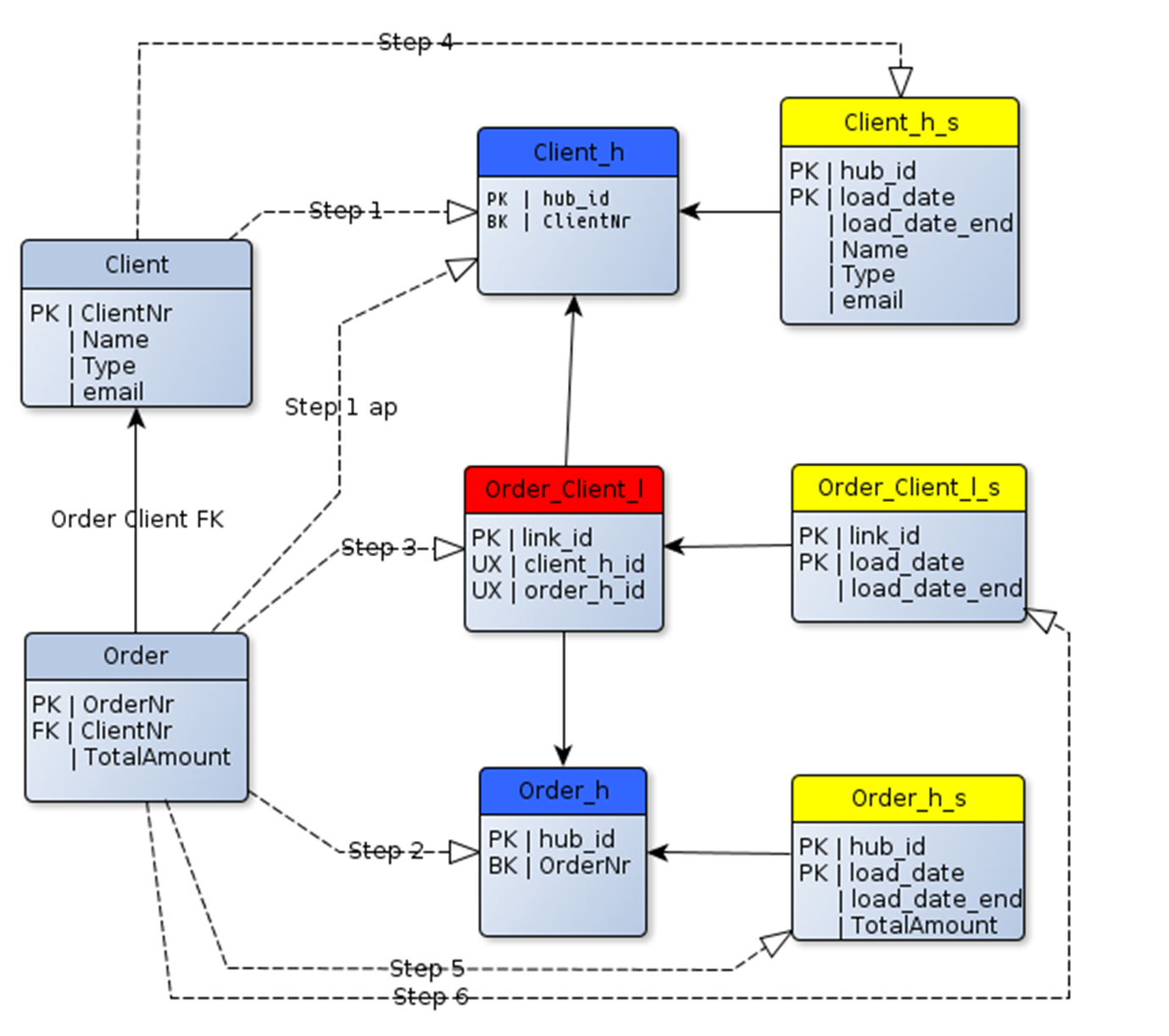
Omdat datavault al een tijd bestaat, is de theorie al best omvangrijk. Zo zijn er de kreten: RAW-VAULT en BUSINESS-VAULT.. Plat gezegd betekent de RAW-VAULT dat we de entiteiten van de bron 1op1 “ver-datavaulten”. Een tabel wordt een hub, een relatie tussen twee tabellen ( foreign-key) wordt een link. Echter de HUB krijgt niet alle attributen van de bron-tabel, de functionele sleutel ofwel de business-key gaat naar de HUB-tabel en de overige attributen worden in één of meerdere satellieten van de hub geplaatst. Bij BUSINESS-VAULT worden entiteiten gevormd die voor de business interessant zijn.
HUB’s, Satellieten en LINK-tabellen zijn gewone tabellen. Datavault is een technische implementatie van een 3e normaalvorm-datamodel waarbij de attributen, foreignkeys en business-keys op een speciale manier verspreid zijn over 3 typen van tabellen ( hub,sat en link)
De datavault-flow
Onderstaande figuur illustreert hoe je een flow creeert. De manier is niets anders als hoe andere flows gemaakt worden, echter, nu zijn de GRIP-functies datavault-specifiek.
Indien de flow gemaakt is, kan hij gestart worden middels het statement:
Exec grip_flow.frun(‘PF_DEMO_DATAVAULT’); Of Exec grip_flow.flow_run(‘PF_DEMO_DATAVAULT’);
Middels select * from grip_job1a_v kan de flow-uitvoer gevolgd worden.. Middels select * from grip_audit1_v kunnen de succesvolle ETL’s van de FLOW gevolgd worden.
Middels select * from grip_log1_v kunnen de sub-stappen van een ETL gevolgd worden. Een actualize_t2 bestaat uit ca 4 opeenvolgende SQL-queries, terwijl een actualize_link met 6 hubs wel uit 10 SQL-queries bestaat.
Datavault-attributen
| Technische datavault attributen | Standaard Warehouseattributen |
|---|---|
| LOAD_DTS | ID , CURR_ID |
| END_LOAD_DTS | DATE_CREATED , AUD_ID_CREATED |
| RECORD_SOURCE | DATE_UPDATED , AUD_ID_UPDATED |
| DATE_DELETED , AUD_ID_DELETED |
De drie technische datavault attributen worden door GRIP bepaald tenzij je ze definieert in de aanleverview van de hub. De andere 8 attributen worden door GRIP bepaald.
Load_dts is de ‘current_timestamp’ van het moment van laden tenzij in de view dit attribuut bepaald wordt.
End_load_dts is bij laden van actuele data door GRIP ‘null’ tenzij dit attribuut in de aanleverview bepaald wordt. Indien RECORD_SOURCE niet door de aanleverview bepaald wordt, krijgt dit attribuut de naam van de aanleverview.
Actualize_hub()
De routine actualize_hub zorgt voor de actualisatie van de Hub en Satelliet. De eerste parameter van de functie-aanroep is de naam van de view waar het databeeld mee bepaald wordt. De tweede parameter is de naam van de HUB-tabel. Deze HUB-tabel wordt gecreëerd op basis business-keys (merge_keys) in de aanroep en van de BRON-view.
Grip_etl.actualize_hub(‘bronview,’Hub,’| commands |’)
Als commands kan ingevuld worden :
MERGE_KEYS
Indien een hub en of satelliet niet bestaat, wordt hij aangemaakt op basis van de structuur van de bron.
Omdat de bron een views is, en meerdere uitgevraagd wordt, wordt daarvan eerst een (temp)tabel gemaakt.
Vervolgens wordt de aangeboden data gecontroleerd op valide business-keys. Deze moeten allemaal gevuld zijn.
Nieuwe business-keys ( merge_keys) worden toegevoegd aan de HUB. Vervolgens wordt het nieuwe actuele satellietbeeld opgebouwd. Dit databeeld bevat alle bron-attributen behalve de business-key-attributen maar aangevuld met de lookup-key van de hub.
De merge-tabel wordt gemaakt op basis van het databeeld van de satelliet en het zojuist samengestelde actuele databeeld. De merge-key in deze is de lookup-id naar de HUB. Met het maken van de merge-table worden de satelliet-attributen van het vorige en huidige databeeld vergeleken. Indien er verschillen wordt attribuut gemuteerd_jn op ‘Y’ gezet.
Op basis van deze waarde blijkt dus dat een satelliet-record gewijzigd is en wordt dat voorkomen afgesloten en de nieuwe actueel voorkomen toegevoegd. E.e.a. gaat gepaard met de juiste setting van date_created en date_deleted. Tenslotte zijn er de voorkomens die geheel nieuw zijn: deze worden toegevoegd aan de satelliet.
Met deze stappen zijn de satelliet en hub tabellen geactualiseerd. De GRIP-routine logt de statements met overeenkomstige omschrijving in de tabel GRIP_LOG waar bovenstaand figuur een dump van is. In de bijlage van dit document wordt de gegenereerde SQL weergegeven.
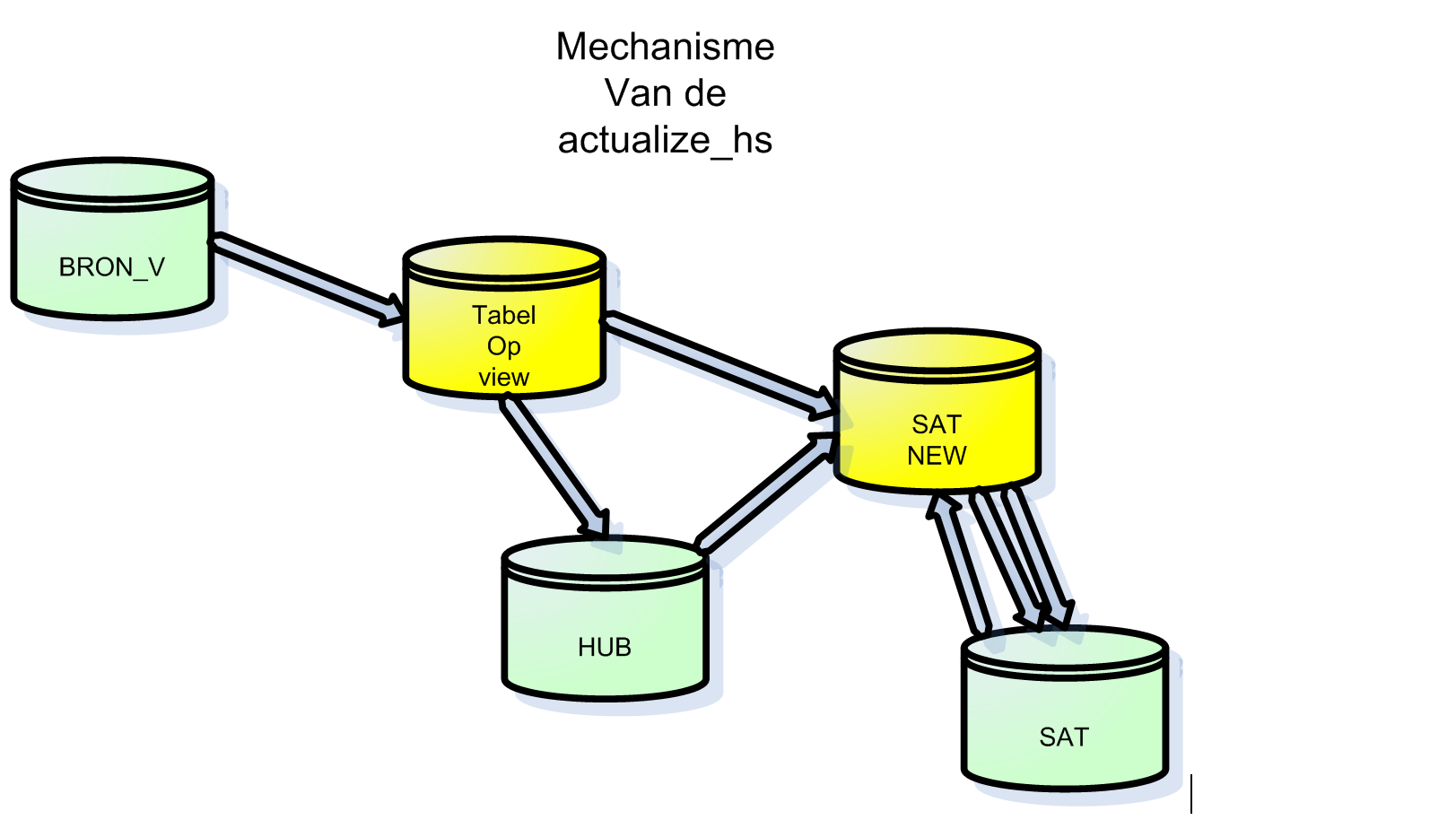
In onderstaande figuur is van onder naar boven het aantal stappen te zien welke uitgevoerd worden bij de actualize_hub. Per stap wordt een sql gegeneeerd welke uitgevoerd wordt. Deze info staat in view grip_log1_v.

Parameters
| nr | parameters | opmerking |
|---|---|---|
| 1 | Tabel of view | |
| 2 | Wordt automatisch aangemaakt | |
| 3 | SAT_IS |
Verplicht, tabel wordt automatisch aangemaakt |
| 4 | MERGE_KEYS |
Verplicht, lijst met businesskeys van de hub. |
| 5 | WHERE |
Optioneel |
Actualize_link()
De link zit tussen 2 of meer hubs en wordt geactualiseerd met de gegevens van de bron-view of tabel. De bron moet
alle business-keys bevatten om voor iedere HUB de koppeling te kunnen maken.
Additionele attributen die betrekking hebben op de LINK kunnen toegvoegd worden aan de satelliet van de link.
Een link hoeft geen satelliet te hebben.
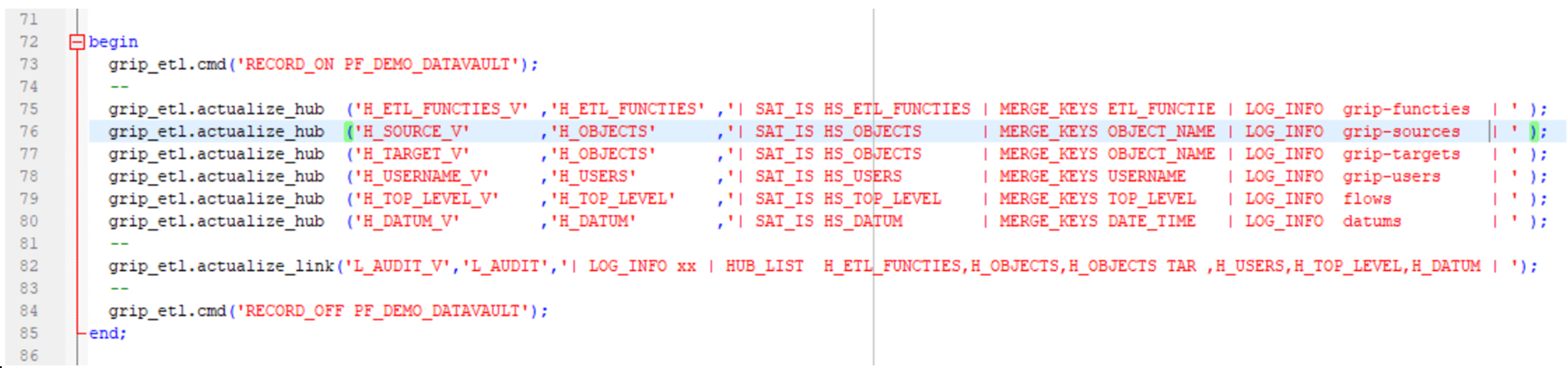
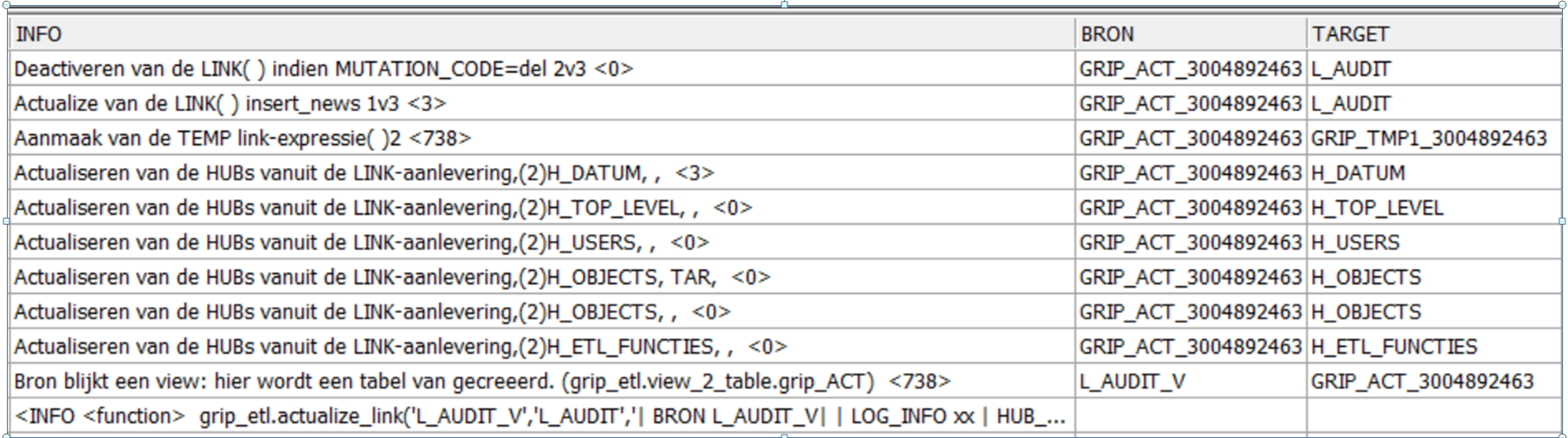
grip_etl.actualize_link('L_AUDIT_V','L_AUDIT_2'
,'| LOG_INFO xx
| HUB_LIST H_ETL_FUNCTIES,H_OBJECTS,H_OBJECTS TAR,H_USERS,H_TOP_LEVEL,H_DATUM | ');
grip_etl.actualize_link('L_AUDIT_V','L_AUDIT_2'
,'| LOG_INFO xx | SAT_IS LS_AUDIT_2
| HUB_LIST H_ETL_FUNCTIES,H_OBJECTS,H_OBJECTS TAR ,H_USERS,H_TOP_LEVEL,H_DATUM | ');
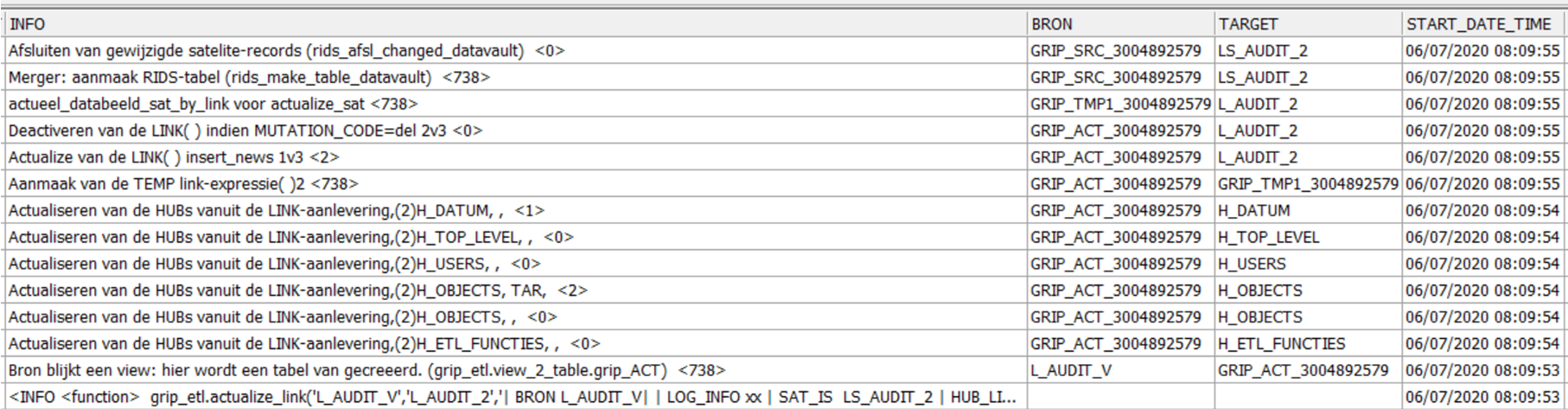
Bovenstaande is het scenario van de link-routine, te lezen van onder naar boven. De eerste stappenlijst is een aanroep zonder Satelliet, de 2e met satelliet.
Als eerste wordt een integral databeeld gemaakt tussen de hubs en de bron. Vervolgens blijkt dat de link en satelliet nog niet bestaan : deze worden aangemaakt. Vervolgens kan de link bijgewerkt worden met eventueel nieuwe linkgegevens. Indien de LINK een satelliet heeft, wordt het actuele satelliet-beeld aangemaakt. Vanaf hier is de verwerking gelijk aan de hub-sat-routine : de merger-tabel wordt aangemaakt met stuur informatie voor het updaten van de satelliet.
De actualize_link in dit voorbeeld heeft 2x een link naar h_objects met als businesskey ‘object_name’ . In de aanleverview dient een van de kolommen de orginele naam ‘object_name’ te hebben, en eventueel andere kolommen naar de zelfde hub dienen vooraf te gaan van een alias. Deze alias dient vermeld te worden, achter de HUB-naam in de aanroep van acyalize_link.
Aanroep: | HUB_LIST h1, h2, h2 a1, h2 a2, h2 a3, h2 a4, h3 |
View: Select h1.bk, h2.bk, h2.a1_bk, h2.a2_bk, h2.a3_bk, h2.a4_bk, h3.bk , k1, k2, k3, k4 from aanlevering_v
Parameters
De eerste 2 parameters zijn voor SOURCE en TARGET, de derde parameter staat voor de commands. Commands is een willekeurige lijst met commando’s, sommige optioneel, sommige niet.
| nr | parameters | -opmerking |
|---|---|---|
| 1 | [ Source] | als view of tabel Tabel of view |
| 2 | [ Tabelnaam] | als hub Wordt automatisch aangemaakt |
| 3 | SAT_IS [ tabel_s] | optioneel, tabel wordt automatisch aangemaakt |
| 4 | HUB_LIST hub1,hub2,hub3 | Verplicht, lijst met hubs waar de link aan moet koppelen. |
Historisch laden van de link
Door in de aanlever_view het attribuut HIST_DATE_CREATED op te nemen, kan er historisch geladen worden. De waarde van HIST_DATE_CREATED komt in DATE_CREATED terecht, en LOAD_DTS zou diezelfde waarde kunnen krijgen, wat in de aanleverview te definieren is.
Constraints en indexen
Zowel de actualize_hs als de actualize_link maakt bij aanmaak indexen, unique-constraints en foreign-keys aan. Hierdoor is het datamodel direct dicht-getimmerd zodat data-integriteit gewaarborgd is en adequate indexen voor de queries. De FK van de satelliet naar de hub krijgt de naamgeving H_TABEL_ID. Primary keys en Unique keys krijgen de naam H_TABLE_UK en H_TABLE_PK.
Uitbreiden van de bron-views.
Zodra 1 van de views aangepast wordt kwa naamgeving, of toevoeging van extra attributen, zullen de targets( hub en of satelliet) handmatig aangepast moeten worden. Indien de fouten in een running-flow plaats vindt, kunnen de targets handmatig uitgebreid worden. Wanneer naamgeving van HUBS en SATELLIETEN aangepast worden, kan dat gevolgen hebben voor de verwerking van de programmatuur : UK-index-naamgeving wordt gebasseerd op de naam van de HUB of LINKS. Ingeval van een ORA-error kan met view GRIP_LOG1_V de gegenereerde SQL verkregen worden om hiermee te gaan debuggen.
Datavault in de GRIP_FLOW.
Zoals alle GRIP_ETL.functies kunnen ook de datavault-flows met record-ON/OFF opgenomen worden in de FLOW. De ETL-aanroepen worden onder een flow-naam opgenomen en kunnen gestart worden middels de flowaanroep grip_flow.frun(‘flownaam’).
Ingeval van een error, betreft het een ora-error-situatie in 1 van de 7 stappen van de ETL-functie. Omdat de actualisatie niet in 1 oracle-transactie is ondergebracht, is de data ‘out-of-order’, ofwel, de actualisatie van de hub, link of sateliet is deels uitgevoerd.
Door de oorzaak van de ORA-error te onderzoeken en op te lossen, kan de ETL-routine weer opgestart worden, middels de aanroep van de flow. Het mechanisme constateert zelf de ‘fout-situatie’ en de foute ETL wordt weer vanaf het begin opgestart. De deel-actualisaties die foutloos uitgevoerd zijn, doen wel hun werk maar hebben verder geen effect, tot dat de foutgelopen deel-actualisatie aan de beurt is. Deze en vervolg-actualisaties doen hun werk en uiteindelijk is de gehele ETL succesvol.
Samengevat
Een behalve de insert-append kan iedere ETL zonder na te denken gestart worden: alleen de eerste keer doet hij zijn actualisatie. Foutgelopen flows kunnen altijd doorgestart worden. Mogen eigenlijk niet halverwege afgebroken worden …
Bridge-views genereren
Tot slot wordt hierbij de bridge-view besproken. Dergelijke views zorgen ervoor dat diverse hubs,satelieten en links samengevoegd worden in een integratie - bridge- view, voor het gemak.
Middels handig gebruik van metadata van oracle kunnen eenvoudig queries gegenereerd worden. Hoewel de functionaliteit voor het onderzoek niet gerealiseerd is, zijn de ideen wel gevormd en wordt handige functionaliteit mogelijk geacht voor datamart-view-generatie en integratie-views voor selfservice-BI.
Een mogelijke gedachte – richting: Opgave van twee hubs Genereren van alle mogelijke routes tussen de twee hubs Verzamelen van alle hubs en satelieten die langs deze routes liggen Selecteer van de hubs en satelieten de attributen voor selectie of filtering Vervolgens kan middels de geselecteerde informatie en de bepaalde routes de query gegenereerd worden.
De bridge-view zou een 3e GRIP-etl-routine worden :
Select Grip_etl.make_bridge(‘HUB’,’HUB’,’route-nr’) from dual
Hieronder is code voor doorontwikkelen van deze bridge-functionaliteit op een later moment.
Example
select replace(replace(grip_etl.str_join('L_AUDIT'),'<DBLINK> ',''),'<WHERE>','WHERE 1=1') from dual
SELECT
T0.RECORD_SOURCE RECORD_SOURCE_0
, T0.LOAD_DTS LOAD_DTS_0
, T0.END_LOAD_DTS END_LOAD_DTS_0
, '| ' D_0_L_AUDIT
, T1.DATE_TIME DATE_TIME_1
, T1.RECORD_SOURCE RECORD_SOURCE_1
, T1.LOAD_DTS LOAD_DTS_1
, T1.END_LOAD_DTS END_LOAD_DTS_1
, '| ' D_1_H_DATUM
, T2.ETL_FUNCTIE ETL_FUNCTIE_2
, T2.RECORD_SOURCE RECORD_SOURCE_2
, T2.LOAD_DTS LOAD_DTS_2
, T2.END_LOAD_DTS END_LOAD_DTS_2
, '| ' D_2_H_ETL_FUNCTIES
, T3.OBJECT_NAME OBJECT_NAME_3
, T3.RECORD_SOURCE RECORD_SOURCE_3
, T3.LOAD_DTS LOAD_DTS_3
, T3.END_LOAD_DTS END_LOAD_DTS_3
, '| ' D_3_H_OBJECTS
, T4.OBJECT_NAME OBJECT_NAME_4
, T4.RECORD_SOURCE RECORD_SOURCE_4
, T4.LOAD_DTS LOAD_DTS_4
, T4.END_LOAD_DTS END_LOAD_DTS_4
, '| ' D_4_H_OBJECTS
, T5.TOP_LEVEL TOP_LEVEL_5
, T5.RECORD_SOURCE RECORD_SOURCE_5
, T5.LOAD_DTS LOAD_DTS_5
, T5.END_LOAD_DTS END_LOAD_DTS_5
, '| ' D_5_H_TOP_LEVEL
, T6.USERNAME USERNAME_6
, T6.RECORD_SOURCE RECORD_SOURCE_6
, T6.LOAD_DTS LOAD_DTS_6
, T6.END_LOAD_DTS END_LOAD_DTS_6
, '| ' D_6_H_USERS
FROM
L_AUDIT T0
,H_DATUM T1
,H_ETL_FUNCTIES T2
,H_OBJECTS T3
,H_OBJECTS T4
,H_TOP_LEVEL T5
,H_USERS T6
WHERE 1=1
and T0.H_DATUM_ID = T1.ID (+)
and T0.H_ETL_FUNCTIES_ID = T2.ID (+)
and T0.H_OBJECTS_ID = T3.ID (+)
and T0.H_OBJECTS_TAR_ID = T4.ID (+)
and T0.H_TOP_LEVEL_ID = T5.ID (+)
and T0.H_USERS_ID = T6.ID (+)
Onderstaande figuur geeft het resultaat van de query weer. Deze bevat dezelfde informatie als de aanvankelijke bron-view.

Point-in-time.
De point-in-time constructie is nog niet geimplementeerd. Het idée bij dit mechanism is een table behorende bij een bridg-view waarbij de time-stamp van rapporteren wordt vastgelegd. Zo kan de data van een fact-table in combinatie met een bridgeview en timestamp zorgen voor 'bevroren data'
GRIP-datavault toepassing
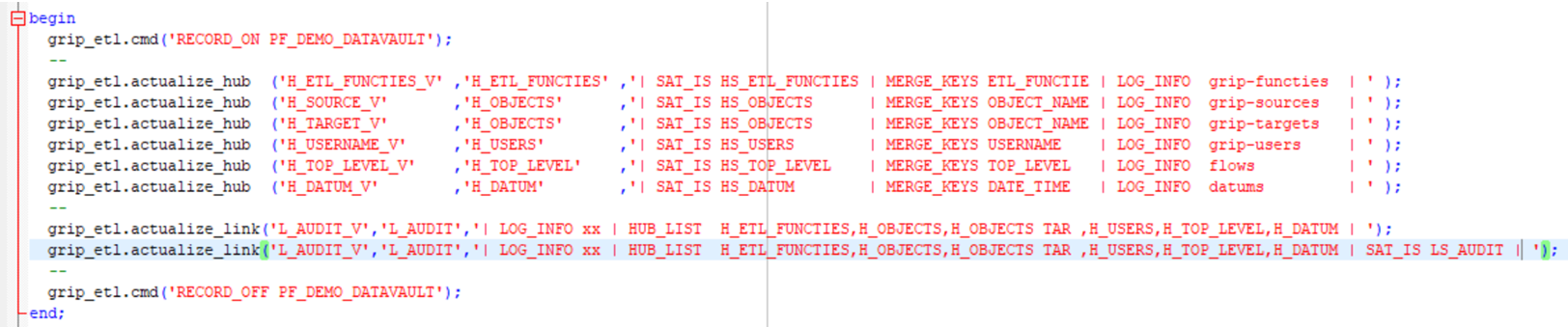
De aanlever-views In dit document wordt als casus de GRIP-tabel GRIP_AUDIT gebruikt als BRON voor een datavault-model. Hieronder de 6 aanleverviews voor de hubs, en als laatste de aanleverview voor de link.
create or replace view h_etl_functies_v
as
select fie ETL_FUNCTIE, sum(1) aantal, min(date_time) min_dat, max(date_time) max_dat
from grip_audit
group by fie
create or replace view h_source_v
as
select nvl(SOURCE_NAME,'LEEG') OBJECT_NAME , sum(1) aantal, min(date_time) min_dat, max(date_time) max_dat
from grip_audit
group by nvl(SOURCE_NAME,'LEEG')
create or replace view h_target_v
as
select nvl(target_NAME,'LEEG') OBJECT_NAME, sum(1) aantal, min(date_time) min_dat, max(date_time) max_dat
from grip_audit
group by nvl(target_NAME,'LEEG')
create or replace view h_username_v
as
select nvl(userNAME,'LEEG') userNAME, sum(1) aantal, min(date_time) min_dat, max(date_time) max_dat
from grip_audit
group by nvl(userNAME,'LEEG')
create or replace view h_top_level_v
as
select nvl(top_level,'LEEG') top_level , sum(1) aantal, min(date_time) min_dat, max(date_time) max_dat
from grip_audit
group by nvl(top_level,'LEEG')
create or replace view h_datum_v
as
select distinct date_time
, DATUM_ID
from grip_audit
, grip_datum_v
where trunc(date_time) = datum
and ( date_time is not null or date_time <> '-1'
create or replace view L_AUDIT_V
as
select distinct fie ETL_FUNCTIE
, source_name OBJECT_NAME
, target_name TAR_OBJECT_NAME
, USERNAME
, TOP_LEVEL
, DATE_TIME, mrg,ins,sel,upd,del,elapse
from grip_audit
laden van de individuele ETL’s
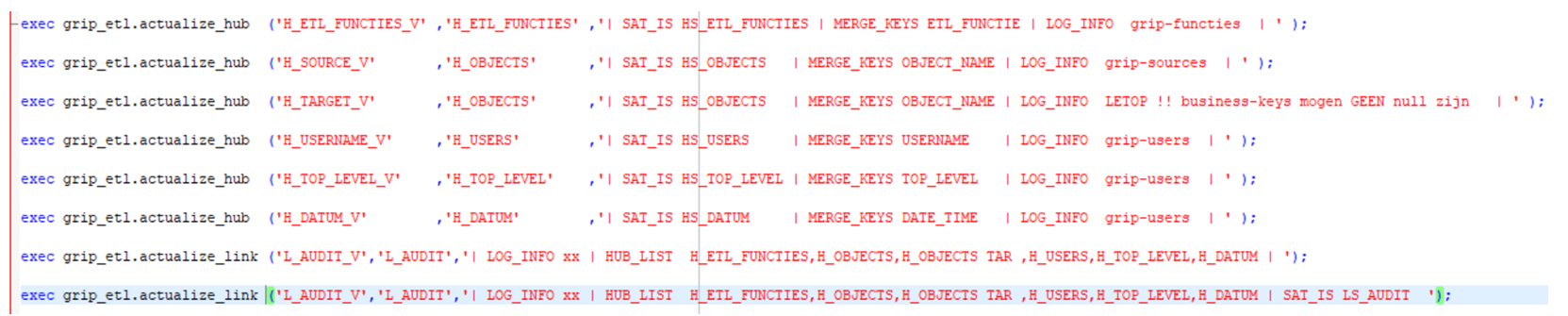
create van een datavault-flow