Vliegende start
Inleiding.
Ieder data warehouse bestaat uit ETL-processen die vanuit een workflow uitgevoerd worden. Soms zijn het heel veel ETL’s , soms zijn het heel veel bronnen, maar met ETL’s en een FLOW van de GRIP-packages kan iedere denkbare constructie ontwikkeld worden. De manier van werken met GRIP dwingt je te denken en oplossen in data-sets, set-based. Hierdoor ben je gedwongen meer generatief ofwel 5gl te denken. Indien een ontwikkelaar procedures en packages gaat ontwikkelen met daarin het gebruik van cursoren is hij in principe op het foute pad. Ieder datawarehouse bestaat voor 100% uit GRIP-aanroepen.
Deze cursus leert je de volgende punten:
- De ETL-routines
- De FLOW
- Logging en debug informatie
- Specials
- Instellen GRIP parameters
De ETL-routines
Je kunt met onderstaande etl-routines ieder denkbare datawarehouse maken.
TRUNC_INSERT ('','','')
INSERT_APPEND('','','')
ACTUALIZE_T1('','','')
ACTUALIZE_T2('','','')
ACTUALIZE('','','')
TAB_CLONE('','','')
TEST_TABLE('','','')
RID_UPDATE('','','')
RID_DELETE('','','')
De routines hebben ieder een specifieke LOAD-taak maar hebben dezelfde parameters :
GRIP_ETL.FIE('BRON','TARGET','COMMANDS')
Template-driven
De routines werken op basis van een specifieke template die in de GRIP-programmatuur vast gelegd is. In de template zijn
query:=' INSERT into <TARGET>
( {DATE_CREATED}
, {AUD_ID_CREATED}
, {CURR_ID}
, <COLS_SEL>
)
SELECT <SYSDATE>
,<AUD_ID_CREATED>
, ''Y'' CURR_ID
, <COLS_SEL>
FROM <SOURCE><DBLINK><WHERE>'
- <TARGET> is een token , een reserved word, die vervangen wordt door de ‘target_tabel’ in de aanroep.
- <SYSDATE> wordt vervangen door string ‘to_date(SYSDATE,’ddmmyyyy hh24:mi:ss’)’
- <COLS_SEL> wordt vervangen door de namen van de attributen van de BRON_VIEW. De namen zijn aan elkaar geplakt met een
comma ertussen : bv ‘naam,straat,woonpaats,postcode’
- <AUD_ID_CREATED> wordt vervangen door de waarde van een grip-sequence.
- <DBLINK> en <WHERE> worden overgenomen uit de waarden die zich in commands bevinden.
Indien COMMANDS := ‘| DBLINK dbl_oud | WHERE date_created > sysdate -2 |’,
wordt met het parsen van de query ,
In geval van {} – tokens, wordt een eventuele afwijkende naam mogelijk. Soms moet grip aansluiten op een bestaand datamodel met andere naamgevingen.
- {DATE_CREATED} wordt standaard vertaald naar DATE_CREATED maar kan eventueel vertaald worden naar CREATE_DATE.
Uiteindelijk zijn alle parameters ingevuld en kan de opgebouwde query uitgevoerd worden door ORACLE.
Het basisprincipe van alle ETL-routines is de data van de bronview te verwerken in een temptabel. Vervolgens wordt dan afhankelijk van de loadingtype , het insert, append of actualisatie template geselecteerd waarmee de doeltabel mee bijgewerkt wordt aan de hand van de data van de temptabel.
Logging
Alleen als de query (ETL) succesvol is, wordt dat in tabel grip_audit gelogd. De opgebouwde query wordt gelogd in tabel grip_log. Geeft de query een ora-eror, wordt ook de error gelogd bij de query. Omdat de etl foutging wordt geen grip_audit-record toegevoegd. Gaat de ETL fout bij aanroep vanuit de flow, wordt een mailtje gestuurd van de query inclusief de log_data. In grip_debug wordt ruimschoots logging geplaatst voor debugging.
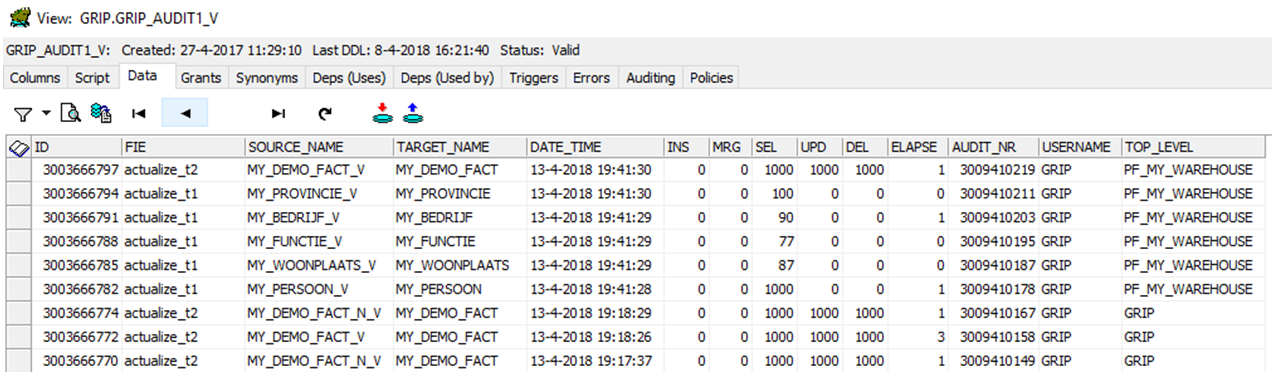
Select * from grip_audit1_v
Select * from grip_debug1_v
Select * from grip_audit1_v
Demodata
Voer steeds de code uit die je tegenkomt. Onderstaande view levert de uitgangsdata voor de cursus.
create or replace view GRIP_DEMO_DATA_V
as
select level id
,'Persoon_' || level persoon
,'Woonplaats_' || mod(level,87) woonplaats
,'Woonplaats_' || to_number(mod(level,47)+2) woonplaats_n
,'Functie_' || mod(level,77) functie
,'Functie_' || to_number(mod(level,43)+2) functie_n
,'Bedrijf_' || to_number(mod(level,89)+3) bedrijf
,'Bedrijf_' || to_number(mod(level,89)+2) bedrijf_n
,'Provincie_' || mod(level,100) provincie
from DUAL
CONNECT BY LEVEL<=1000;
select * from GRIP_DEMO_DATA_V
where provincie ='Provincie_2';
Werkwijze van de cursus
Door zelf aan de knoppen te zitten en de werking van GRIP te voelen en te ervaren ben je snel in staat zelfstandig met GRIP ETL’s te ontwerpen .
Er kan ingelogd worden met TOAD , SQL Developer of Dbeaver. Vraag aan je collega/instructor waar je aan kan loggen voor deze cursus.
Als laatste opdracht wordt een compleet warehouse gebouwd. Het lijkt heel eenvoudig en dat is het ook. De complexiteit moet niet in de
solution en techniek zitten maar in de business-rules, ofwel de oracle-views: dat is al complex genoeg.
Trunc_insert()
Van de trunc-insert bestaan 4 typen. GRIP is geëvolueerd tot de versie die nu gebruikt wordt bij Schiphol en Achmea. In de toekomst kunnen voor specifieke klanten ETL-routines wenselijk zijn die vervolgens aan GRIP toegevoegd worden.
De huidige routines bestaan:
Grip_etl.trunc_insert('','','')
Grip_etl.trunc_insert_1('','','')
Grip_etl.trunc_insert_ss('','','')
Grip_etl.trunc_insert_ss_2('','','')
Het verschil zit hem in de templates. Trunc_insert_1 heeft als extra de {ID} die een ‘dure’ sequence gebruikt die voor sommige situaties juist weer handig zijn. De _ss variant staat voor same_structure hetgeen betekent dat de structuur van bron en target identiek moet zijn. De _ss_2 variant is niet een zuivere same_as: alle bron-attributen moeten in de target-tabel zitten maar de target-tabel mag ook nog andere attributen hebben die op een andere ETL bevoorraad worden.
Uitvoeren en controle
exec grip_etl.trunc_insert('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO tabel creatie op basis van view structuur |')
select * from MY_DEMO_DATA_1;
select * from grip_audit1_v;

select * from grip_debug1_v;

select * from grip_log1_v;

In attribuut SQL_STATEMENT ( CLOB ) van view grip_log1_v staat de sql-query die uitgevoerd is.
Fout in de ETL
Wanneer we een foute query uitvoeren krijgt men de volgende logging en schermen:
exec grip_etl.trunc_insert('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| WHERE persoon = 1 | LOG_INFO tabel creatie op basis van view structuur | ');
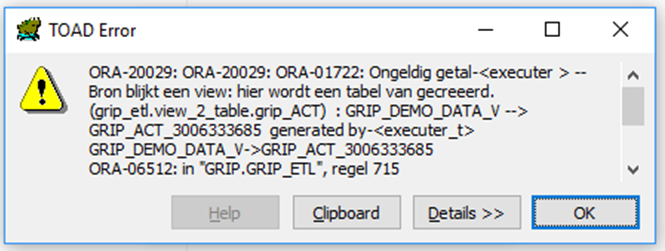
select * from grip_log1_v;

In attribuut SQL_STATEMENT staat de query die uitgevoerd werd.

exec grip_etl.trunc_insert_1('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO tabel creatie op basis van view structuur |');
select * from MY_DEMO_DATA_1;-- ID is nu gevuld
select * from grip_audit1_v;-- let op kolom fie
select * from grip_debug1_v; -- deze GRIP-views tonen altijd de laatste loggings bovenaan,
select * from grip_log1_v;-- check de sequence
exec grip_etl.trunc_insert_ss('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO tabel creatie op basis van view structuur |')
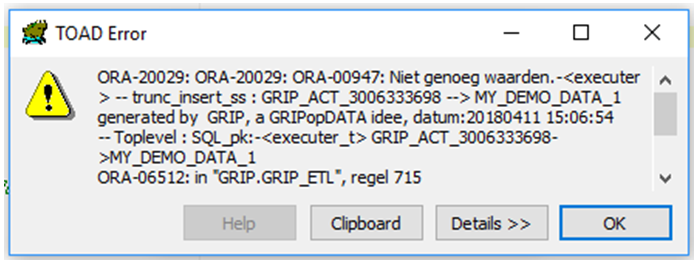
De structuur van de target-tabel is niet juist … het handigste is de tabel te droppen, en het statement nogmaals uit te voeren :
De target wordt altijd aangemaakt op de structuur van de view. Als extra worden de 8 datawarehouse-attributen toegevoegd :
de proces-attributen.
Indien deze attributen in de bronview voorkomen, worden ze gefilterd. De proces-attributen van de target worden door GRIP bepaald.
Zijn de bron-proces-attributen van belang, moet je de ander een andere naam in de view doorgeven.
ID, DATE_CREATED,AUD_ID_CREATED, DATE_UPDATED,AUD_ID_UPDATED, DATE_DELETED,AUD_ID_DELETED,CURR_ID
Bij de SS-tabel worden deze attributen NIET gebruikt.
drop table MY_DEMO_DATA_1;
select * from MY_DEMO_DATA_1;-- constateer het ontbreken van de warehouse-attributen
select * from grip_audit1_v;-- let op kolom fie
select * from grip_debug1_v;-- deze GRIP-views tonen altijd de laatste loggings bovenaan,
select * from grip_log1_v;-- check de sequence

exec grip_etl.trunc_insert_ss_2('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO tabel creatieop basis van view structuur |');
select * from MY_DEMO_DATA_1;-- ID is nu gevuld
select * from grip_audit1_v;-- let op kolom fie
select * from grip_debug1_v;-- deze GRIP-views tonen altijd de laatste loggings bovenaan,
select * from grip_log1_v;-- check de sequence
in de log-tabel is een andere insert-statement te zien:
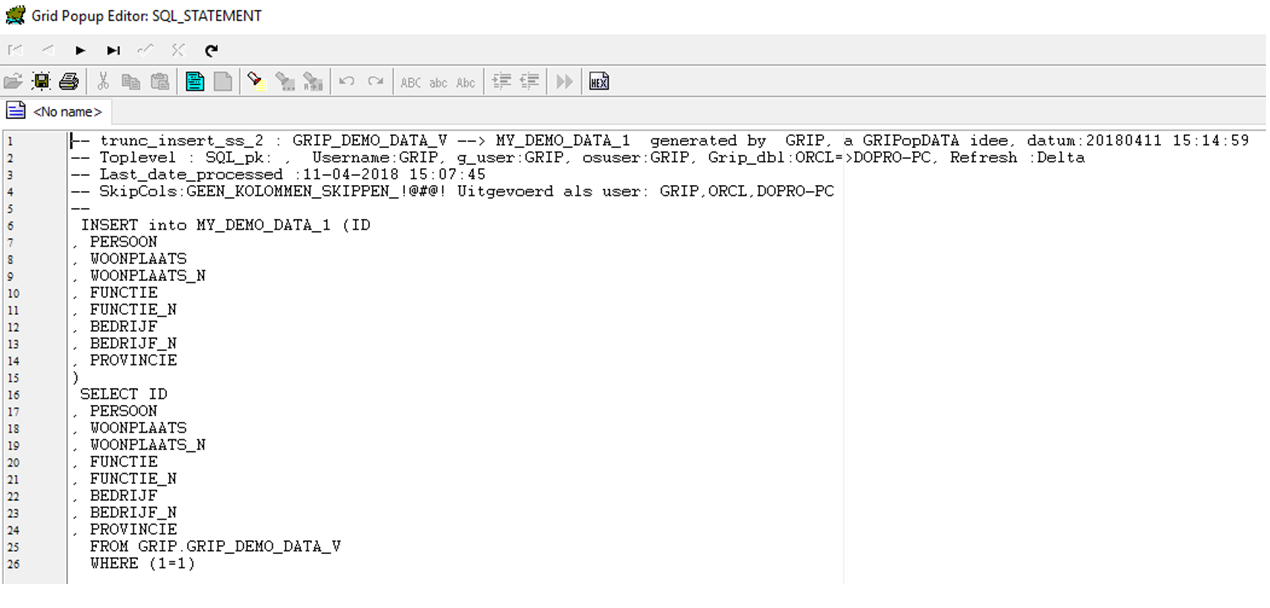
Samenvatting
Met GRIP-ETL-processing is sprake van de data en het processen van de data. De business-rules als filteren transformeren, joinen, verrijken,aggregeren en
dergelijke, vinden allemaal plaats in de VIEW.
De data die daaruit tevoorschijn komt, komt terecht in een temp-tabel. Het verwerken of laden van deze data in de target-tabel geschied middels de
templates van de GRIP-etl-routine.
Iedere GRIP-etl-routine heeft zijn specifieke laadtype en zijn eigen set van templates. We hebben nu de TRUNC_INSERT onder de knie en gaan nu de INSERT_APPEND bestuderen. Je zult zien dat die routine als mechanisme niet veel anders dan de TRUNC_INSERT.
Insert_append()
Van de insert-append bestaan 3 typen. GRIP is geëvolueerd tot de versie die nu gebruikt wordt bij Schiphol en Achmea. In de toekomst kunnen voor specifieke klanten
ETL-routines wenselijk zijn die vervolgens aan GRIP toegevoegd worden.
De huidige routines bestaan:
Grip_etl.insert_append('','','')
Grip_etl.insert_append_ss('','','')
Grip_etl.insert_append_ss_2('','','')
templates
Het onderlinge verschil zit hem in de templates, en wel als volgt:
INSERT into <TARGET> ( {ID}, {DATE_CREATED}, {AUD_ID_CREATED}, {CURR_ID}, <COLS_SEL> )
select <ID_SEQ>, <SYSDATE>, <AUD_ID_CREATED>, ''Y'' , <COLS_SEL>
from <SOURCE><DBLINK> a
<WHERE>/*grip_etl.insert_append*/
INSERT into <TARGET>
select * from <SOURCE><DBLINK>
<WHERE>/*grip_etl.insert_append_ss*/
INSERT <APPEND_HINT> into <TARGET> (<COLS_SEL>)
SELECT <COLS_SEL> FROM <SOURCE><DBLINK>
<WHERE>/*grip_etl.insert_append_ss_2*/
Voeruit :
drop table MY_DEMO_DATA_1
exec grip_etl.insert_append('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO tabel creatie op basis van view structuur |');
-- voer 5x uit
select * from MY_DEMO_DATA_1;
-- bestudeer de vulling van de tabellen, let mn op de ID,DAT_CREATED - kolommen
select * from grip_audit1_v;
-- zie de laatste 5 regels
select * from grip_log1_v;
-- bestudeer de SQL_STATEMENT
drop table MY_DEMO_DATA_1
exec grip_etl.insert_append_ss('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO tabel creatie op basis van view structuur |');
-- voer 5x uit
select * from MY_DEMO_DATA_1;
-- bestudeer de vulling van de tabellen, let mn op de ID,DAT_CREATED - kolommen
select * from grip_audit1_v;-- zie de laatste 5 regels
select * from grip_log1_v;-- bestudeer de SQL_STATEMENT
drop table MY_DEMO_DATA_1;
exec grip_etl.insert_append_ss_2('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO tabel creatie op basis van view structuur |');
-- voer 5x uit
select * from MY_DEMO_DATA_1;
-- bestudeer de vulling van de tabellen, let mn op de ID,DAT_CREATED - kolommen
select * from grip_audit1_v;-- zie de laatste 5 regels
select * from grip_log1_v;-- bestudeer de SQL_STATEMENT
Actualize()
Van de actualize bestaan ook 3 typen. De actualize-routine is de oer-routine van GRIP en verwerkt FULL-aanleveringen op een type-2 wijze: gewijzigde
records worden in de target-tabel afgesloten en de actuele records toegevoegd. Nieuwe records worden toegevoegd en records in de target-tabel die niet
meer door de bron aangeleverd wordt, worden afgesloten.
Voor delta-aanleveringen kan de actualize_t1 of actualize_t2 gebruikt worden. Met de Type-t1 wordt bij een wijziging van een voorkomen, het target-record
geüpdatet. Daarbij worden de attributen DATE_UPDATED en AUD_ID_UPDATED bijgewerkt met de sysdate en de audit_id.
Bij gebruik van de type-T2 geldt hetzelfde verhaal als bij de actualize echter kan met een delta-aanlevering gewerkt worden: niet alle bron-data behoeft
aangeleverd te worden maar slechts nieuwe en gewijzigde. Verdwenen records in de bron worden met deze functie niet verwijderd.
Ook hier worden de attributen DATE_UPDATED en AUD_ID_UPDATED en DATE_DELETED en AUD_ID_DELETED en CURR_ID gebruikt. CURR_ID=’Y’ staat voor een actueel record. Voor dit record is DATE_DELETED vanzelfsprekend leeg.
De actualize-routines hebben ieder 4 templates: de data wordt in 4 etappes op efficiënte manier verwerkt.
Actualize(’’,’’,’’)
Voer het volgende uit:
exec grip_etl.trunc_insert('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO tabel creatie op basis van view structuur |');
-- voer 1x uit
exec grip_etl.actualize('MY_DEMO_DATA_1','MY_DEMO_DATA_2','| LOG_INFO tabel creatie op basis van view structuur |');
-- voer 1x uit
select * from MY_DEMO_DATA_2 order by person;
update MY_DEMO_DATA_1 set persoon = persoon || 'a'where persoon ='Persoon_1';
exec grip_etl.actualize ('MY_DEMO_DATA_1','MY_DEMO_DATA_2','| LOG_INFO tabel creatie op basis van view structuur |');
-- voer 1x uit
select * from MY_DEMO_DATA_2 order by person;

select * from grip_log1_v;-- bestudeer de SQL_STATEMENT

select * from grip_audit1_v;-- zie de laatste 5 regels

Templates
Nieuwe voorkomens
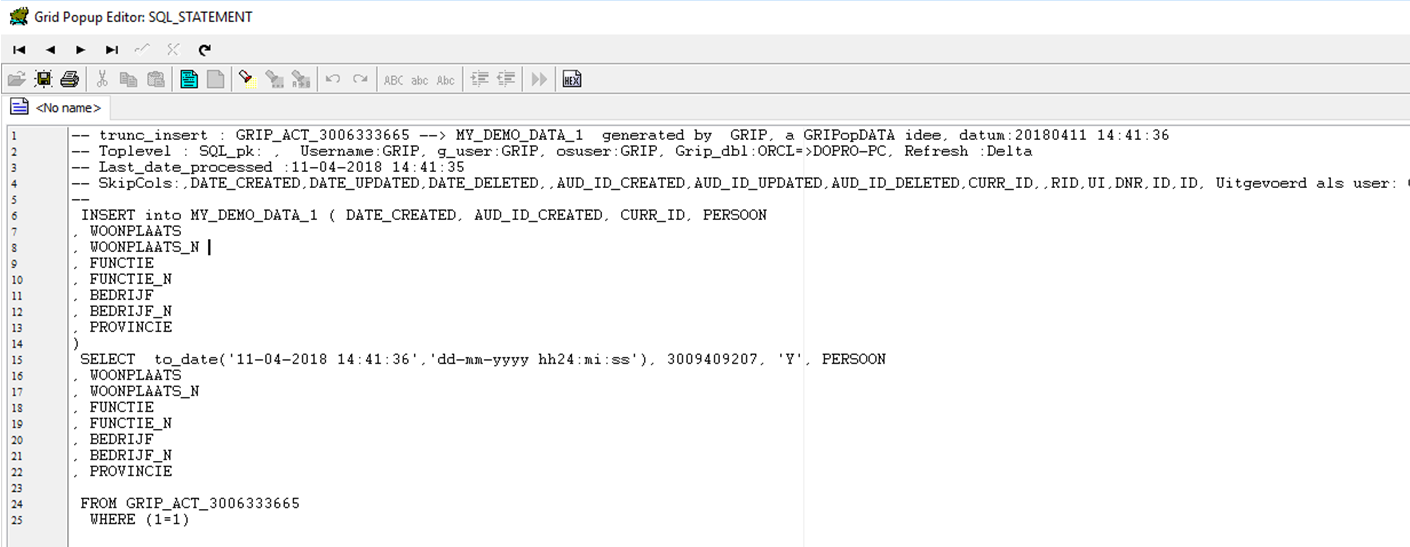
1/4 Bepaling nieuwe voorkomens:
-- <ACTUALIZE>Bepaling nieuwe voorkomens : MY_DEMO_DATA_1 --> MY_DEMO_DATA_2 generated by GRIP, a GRIPopDATA idee, datum:20180411 16:37:56
-- Toplevel : SQL_pk: , Username:GRIP, g_user:GRIP, osuser:GRIP, Grip_dbl:ORCL=>DOPRO-PC, Refresh :Delta
-- Last_date_processed :11-04-2018 16:37:19
-- SkipCols:,DATE_CREATED,DATE_UPDATED,DATE_DELETED,,AUD_ID_CREATED,AUD_ID_UPDATED,AUD_ID_DELETED,CURR_ID,,RID,UI,DNR,ID,ID, Uitgevoerd als user: GRIP,ORCL,DOPRO-PC
--
CREATE TABLE GRIP_TMP1_3006333868 as
SELECT 'TEST' UI ,PERSOON
, WOONPLAATS
, WOONPLAATS_N
, FUNCTIE
, FUNCTIE_N
, BEDRIJF
, BEDRIJF_N
, PROVINCIE
from GRIP.MY_DEMO_DATA_1 WHERE (1=1)
minus
SELECT 'TEST' UI ,PERSOON
, WOONPLAATS
, WOONPLAATS_N
, FUNCTIE
, FUNCTIE_N
, BEDRIJF
, BEDRIJF_N
, PROVINCIE
from MY_DEMO_DATA_2 WHERE (1=1) AND DATE_DELETED is null
Oude voorkomens
2/4 Bepaling oude voorkomens
-- <ACTUALIZE>Bepaling oude voorkomens : MY_DEMO_DATA_1 --> MY_DEMO_DATA_2 generated by GRIP, a GRIPopDATA idee, datum:20180411 16:37:56
-- Toplevel : SQL_pk: , Username:GRIP, g_user:GRIP, osuser:GRIP, Grip_dbl:ORCL=>DOPRO-PC, Refresh :Delta
-- Last_date_processed :11-04-2018 16:37:19
-- SkipCols:,DATE_CREATED,DATE_UPDATED,DATE_DELETED,,AUD_ID_CREATED,AUD_ID_UPDATED,AUD_ID_DELETED,CURR_ID,,RID,UI,DNR,ID,ID, Uitgevoerd als user: GRIP,ORCL,DOPRO-PC
--
CREATE TABLE GRIP_TMP2_3006333868 as
SELECT 'PROD' UI ,PERSOON
, WOONPLAATS
, WOONPLAATS_N
, FUNCTIE
, FUNCTIE_N
, BEDRIJF
, BEDRIJF_N
, PROVINCIE
from MY_DEMO_DATA_2 WHERE (1=1) AND DATE_DELETED is null
minus
SELECT 'PROD' UI ,PERSOON
, WOONPLAATS
, WOONPLAATS_N
, FUNCTIE
, FUNCTIE_N
, BEDRIJF
, BEDRIJF_N
, PROVINCIE
from GRIP.MY_DEMO_DATA_1 WHERE (1=1)
Toevoegen nieuw
3/4 Toevoegen nieuwe voorkomens aan target
-- <ACTUALIZE>Toevoegen nieuwe voorkomens aan target : MY_DEMO_DATA_1 --> MY_DEMO_DATA_2 generated by GRIP, a GRIPopDATA idee, datum:20180411 16:37:56
-- Toplevel : SQL_pk: , Username:GRIP, g_user:GRIP, osuser:GRIP, Grip_dbl:ORCL=>DOPRO-PC, Refresh :Delta
-- Last_date_processed :11-04-2018 16:37:19
-- SkipCols:,DATE_CREATED,DATE_UPDATED,DATE_DELETED,,AUD_ID_CREATED,AUD_ID_UPDATED,AUD_ID_DELETED,CURR_ID,,RID,UI,DNR,ID,ID, Uitgevoerd als user: GRIP,ORCL,DOPRO-PC
--
INSERT into MY_DEMO_DATA_2
( PERSOON
, WOONPLAATS
, WOONPLAATS_N
, FUNCTIE
, FUNCTIE_N
, BEDRIJF
, BEDRIJF_N
, PROVINCIE
, DATE_CREATED , ID , AUD_ID_CREATED, CURR_ID )
SELECT PERSOON
, WOONPLAATS
, WOONPLAATS_N
, FUNCTIE
, FUNCTIE_N
, BEDRIJF
, BEDRIJF_N
, PROVINCIE
, to_date('11-04-2018 16:37:56','dd-mm-yyyy hh24:mi:ss') , GRIP_SEQ_ID.NEXTVAL , 3009409466, 'Y'
from GRIP_TMP1_3006333868
Afsluiten oud
4/4 afsluiten oude voorkomens in target
-- <ACTUALIZE>afsluiten oude voorkomens in target : MY_DEMO_DATA_1 --> MY_DEMO_DATA_2 generated by GRIP, a GRIPopDATA idee, datum:20180411 16:37:56
-- Toplevel : SQL_pk: , Username:GRIP, g_user:GRIP, osuser:GRIP, Grip_dbl:ORCL=>DOPRO-PC, Refresh :Delta
-- Last_date_processed :11-04-2018 16:37:19
-- SkipCols:,DATE_CREATED,DATE_UPDATED,DATE_DELETED,,AUD_ID_CREATED,AUD_ID_UPDATED,AUD_ID_DELETED,CURR_ID,,RID,UI,DNR,ID,ID, Uitgevoerd als user: GRIP,ORCL,DOPRO-PC
--
UPDATE MY_DEMO_DATA_2
set DATE_DELETED = to_date('11-04-2018 16:37:56','dd-mm-yyyy hh24:mi:ss')
, AUD_ID_DELETED = 3009409466
, CURR_ID = 'N'
where rowid in
( select rowid from MY_DEMO_DATA_2
where ( nvl(PERSOON,'#__#')
, nvl(WOONPLAATS,'#__#')
, nvl(WOONPLAATS_N,'#__#')
, nvl(FUNCTIE,'#__#')
, nvl(FUNCTIE_N,'#__#')
, nvl(BEDRIJF,'#__#')
, nvl(BEDRIJF_N,'#__#')
, nvl(PROVINCIE,'#__#')
) in
( select nvl(PERSOON,'#__#')
, nvl(WOONPLAATS,'#__#')
, nvl(WOONPLAATS_N,'#__#')
, nvl(FUNCTIE,'#__#')
, nvl(FUNCTIE_N,'#__#')
, nvl(BEDRIJF,'#__#')
, nvl(BEDRIJF_N,'#__#')
, nvl(PROVINCIE,'#__#')
from GRIP_TMP2_3006333868
)
) AND DATE_DELETED is null
exec grip_etl.actualize ('MY_DEMO_DATA_1','MY_DEMO_DATA_2','| LOG_INFO tabel creatie op basis van view structuur |');
-- voer 5x uit
select * from grip_audit1_v;-- stel vast dat er 1 record (van persoon_1) afgesloten is
select * from MY_DEMO_DATA_2 where curr_id ='N';
Actualize_t1
actualize_t1(’bron’,’target’,’| MERGE_KEYS k1,k2 |’)
De actualize_t1 actualiseert de target met data van de bron. De bron en de target worden met elkaar geouter-joined op basis van de MERGE_KEYS. Records die niet in de target zitten, worden toegevoegd, van de records die op basis van de merge-key in beide tabellen zit, worden alle attributen vergeleken en indien er verschillen zijn, worden allen voor die verschillen een update uitgevoerd.
De actualize_t1 werkt als volgt, voer uit:
exec grip_etl.trunc_insert('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO tabel creatie op basis van view structuur |');
-- voer 1x uit
exec grip_etl.actualize_t1('MY_DEMO_DATA_1','MY_DEMO_DATA_3','| MERGE_KEYS PERSOON |');
-- voer 5x uit
update MY_DEMO_DATA_1 set woonplaats = woonplaats || 'a'whererownum<100;
-- voer 1x uit
exec grip_etl.actualize_t1('MY_DEMO_DATA_1','MY_DEMO_DATA_3','| MERGE_KEYS PERSOON |');
-- voer 5x uit
select * from grip_audit1_v;
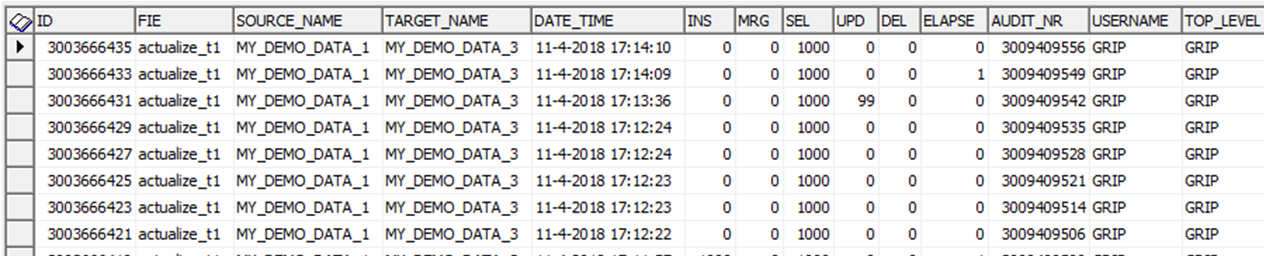
De 99 updates zijn uitgevoerd met aud_id_updated 3009409542.
Onder dit nummer kun je de gevallen in de target terug vinden:
select * from MY_DEMO_DATA_3 where aud_id_updated =<AUDIT_NR uit de vorige query>

Actualize_t2
actualize_t2(’bron’,’target’,’| MERGE_KEYS k1,k2 |’)
Voor de t2 variant geldt hetzelfde verhaal echter vindt geenupdate plaats maar een “delete” van het target record waarvan de bron-record een of
andere attributen anders heeft, en het gewijzigde bron-record wordt toegevoegd aan de target-tabel. Op deze wijze zijn de wijzigingen van een
businesskey in de tijd navolgbaar.
Bij het afsluiten of “deleten” , vindt geen fysieke delete plaats maar wordt de CURR_ID op ‘N’ gezet en krijgt de date_deleted de waarde van SYSDATE.
Voer uit:
exec grip_etl.trunc_insert ('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO tabel creatie op basis van view structuur |');
-- voer 1x uit
exec grip_etl.actualize_t2('MY_DEMO_DATA_1','MY_DEMO_DATA_4','| MERGE_KEYS PERSOON |');
-- voer 1x uit
update MY_DEMO_DATA_1 set woonplaats = woonplaats || 'a'whererownum<4;
-- voer 1x uit
exec grip_etl.actualize_t2('MY_DEMO_DATA_1','MY_DEMO_DATA_4','| MERGE_KEYS PERSOON |');
-- voer 5x uit
select * from grip_audit1_v;

select * from MY_DEMO_DATA_4
where aud_id_deleted =<aud_id_deleted uit de eerste query>
or aud_id_updated =<aud_id_updated uit de eerste query>;

select * from grip_log1_v;

Tab_clone()
De tabclone was aanvankelijk bedoeld om complete schema’s te klonen naar andere schema’s. Uiteindelijk zou dat ook met de trunc_insert kunnen. De tabclone
haalt de indexen en foreignkeys er eerst af, pompt de data over en zet daarna de indexen en foreignkeys er weer op.
In geval van een ORA-error geeft de routine geen error-status en zal de flow niet stoppen in error maar zal de volgende tabclone uitgevoerd worden.
De error wordt gelogd.
De tabclone is handig in gebruik wanneer je in acceptatie een clone wilt hebben van productie. Vaak wordt de data via een databaselink overgehaald.
- Tabclone(’’,’’,’’)
exec grip_etl.trunc_insert('MY_DEMO_DATA_1','MY_DEMO_DATA_5','||');
select * from grip_debug1_v;
exec grip_etl.tabclone ('MY_DEMO_DATA_1','MY_DEMO_DATA_5','| LOG_INFO clonen van tabel 1 in 5 |');
-- voer 1x uit
select * from grip_log1_v;-- bestudeer de sql_statement
select * from grip_audit1_v;-- je ziet geen tabclone ..
select * from grip_audit order by id desc;-- de view laat geen tabclone-data zien ..
select * from grip_debug1_v;-- te zien is het enabelen en disablenen van indexen en foreignkeys
- Tabclone_2(’’,’’,’’)
Deze ETL-routine doet hetzelfde als de tabclone echter kan deze routine tegen verschil in attributen. Indien er attribuutverschillen zijn, dan wordt daarvan een melding gemaakt in grip_debug.
Table_compare()
- TEST_TABLE('','','')
Van deze routines bestaan 2 varianten : de test_table_tc en de test_table_rc. Beide routines comparen de bron (default TEST) met de target (default PROD)
waarbij de RC variant ook de gerelateerde tabellen meeneemt in de compare. Middels COMMAND ‘SKIPCOLS’ kan opgegeven worden welke kolommen niet meegenomen
moeten worden in de compare. Het resultaat van de compare komt in tabel ‘
exec grip_etl.trunc_insert('MY_DEMO_DATA_1','MY_DEMO_DATA_6','||');
exec grip_etl.trunc_insert('MY_DEMO_DATA_1','MY_DEMO_DATA_7','||');
update MY_DEMO_DATA_7 set woonplaats = woonplaats || 'd'whererownum<3;
exec grip_etl.test_table_tc('MY_DEMO_DATA_1','MY_DEMO_DATA_7','| MERGE_KEYS PERSOON |');
select * from MY_DEMO_DATA_1_TC;

select * from GRIP_DIFF1;

select * from GRIP_DIFF2;

select * from GRIP_DIFF3;

select * from grip_regressie_v;

NB: command TCODE, indien ingevuld, geeft de UI voor de source tabel (default TEST) en TBCODE, indien ingevuld, geeft de UI voor de target tabel (default PROD)
in de tabel
LET OP: de waarden moeten wel als string (max 4 lang) worden meegegeven.
exec grip_etl.test_table_tc('MY_DEMO_DATA_1','MY_DEMO_DATA_7','| MERGE_KEYS PERSOON | TCODE ''DAT1'' | TBCODE ''DAT7'' |');
select * from MY_DEMO_DATA_1_TC;
Rid_update() en Rid_delete()
De rid_update en rid_delete zijn 2 ETL-functies die beiden de targettabel updaten: de rid_update heeft als doel een of meerdere attributen van de target-tabel
te updaten, de rid_delete heeft als doel de target-records af te sluiten of fysiek te verwijderen. In de bron-view dient het attribuut RID voor te komen die
staat voor het row_id van de target-tabel. In de bronview moet dus een join zijn met de target-tabel om de rowid te verkrijgen.
De RID is in plaats van de MERGE_KEY en is de business-key van de targettabel. Feitelijk wordt middels de RID een mutatie-index-tabel gemaakt waarbij heel snel een tabel geüpdatet kan worden.
exec grip_etl.trunc_insert('MY_DEMO_DATA_1','MY_DEMO_DATA_6','||');
create or replace view MY_DEMO_DATA_6_RU_V
as
select x.rowid rid,'Groningen' provincie
from MY_DEMO_DATA_6 x
where instr(bedrijf,'5')>0;

select * from grip_audit1_v;
select * from grip_log1_v;

De query ziet er als volgt uit:
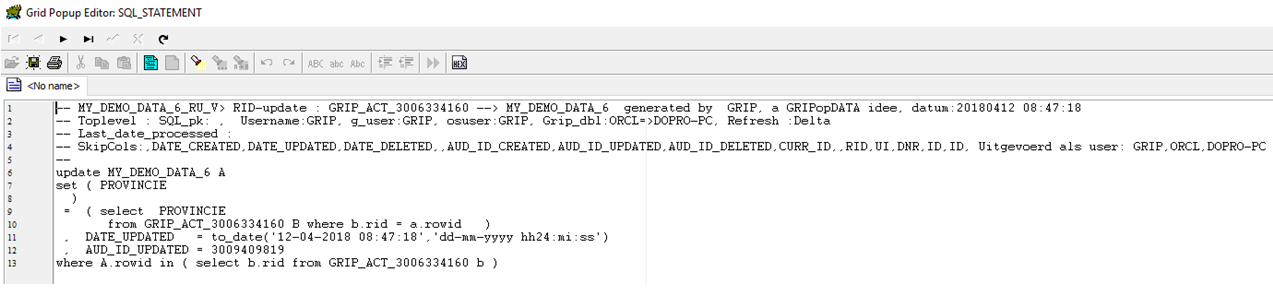
exec grip_etl.rid_update_1('MY_DEMO_DATA_6_RU_V','MY_DEMO_DATA_6','||');
De rid_update en rid_update_1 hebben als verschil dat bij rid_update_1 het attribuut
select x.rowid rid, x.*
from MY_DEMO_DATA_6 x
where instr(bedrijf,'5')>0;
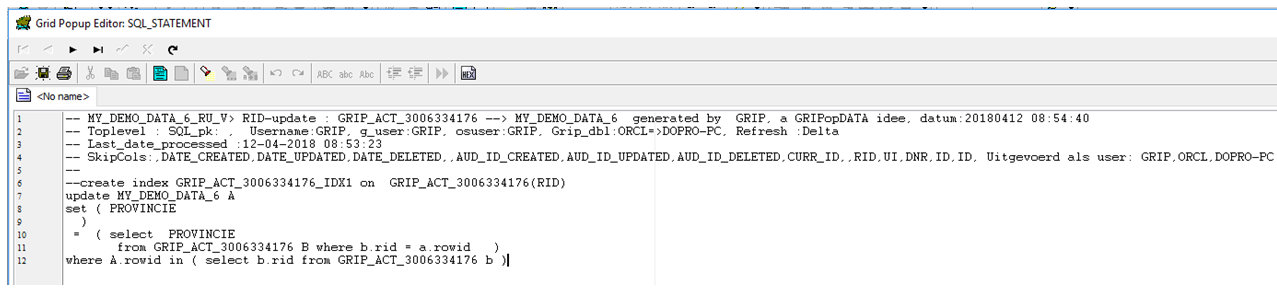
exec grip_etl.rid_set_deleted('MY_DEMO_DATA_6_RU_V','MY_DEMO_DATA_6','||');
select * from grip_audit1_v;


exec grip_etl.rid_delete ('MY_DEMO_DATA_6_RU_V' ,'MY_DEMO_DATA_6' ,'| LOG_INFO xx |')
select * from grip_audit1_v

De Flow
De flow van GRIP is heel eenvoudig in omgang. Door eenvoudig grip_etl.cmd(‘RECORD_ON PF_CURSUS_MAIN‘ ) en grip_etl.cmd(‘RECORD_OFF‘ ) te plaatsen om de ETL-aanroepen, en uit te voeren, zal de ETL niet gaan dataprocessen maar wordt de ETL-calls in de flow PF_CURSUS_MAIN opgenomen.
Eerst wordt eventuele content van PF_CURSUS_MAIN geheel verwijderd .
Record_on record_off
begin
grip_etl.cmd('RECORD_ON PF_CURSUS_MAIN');
--
grip_etl.trunc_insert ('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO demo |');
grip_etl.actualize_t2 ('MY_DEMO_DATA_1','MY_DEMO_DATA_4','| MERGE_KEYS PERSOON |');
--
grip_etl.exec('update MY_DEMO_DATA_1 set woonplaats = woonplaats||''a'' where rownum < 4');
--
grip_etl.actualize_t2 ('MY_DEMO_DATA_1','MY_DEMO_DATA_4','| MERGE_KEYS PERSOON | ');
--
grip_etl.record_job('PF_CURSUS_MAIN','PF_SLEEPER','FLOW');
--
grip_etl.cmd('RECORD_OFF ');
end;
begin
grip_etl.cmd('RECORD_ON PF_SLEEPER');
--
grip_etl.record_job('PF_SLEEPER','dbms_lock.sleep(2)','SQLCALL');
grip_etl.record_job('PF_SLEEPER','dbms_lock.sleep(2)','SQLCALL');
grip_etl.record_job('PF_SLEEPER','dbms_lock.sleep(2)','SQLCALL');
grip_etl.record_job('PF_SLEEPER','dbms_lock.sleep(2)','SQLCALL');
--
grip_etl.cmd('RECORD_OFF ');
end;
Het starten van de FLOW kan op 2 manieren. Via de frun wordt een job gestart van waaruit de flow_run opgestart wordt. Zo heeft men de databasebrowser beschikbaar en hoeft niet naar een zandloper gekeken worden.
Door snel view grip_job1a_v te bevragen, krijgt men overzicht van de lopende flow, zolang hij loopt. Treedt er een error op, zal de status van die ETL op ‘E_error’ gaan staan en wordt een mailtje gestuurd met de ora-error.
exec grip_flow.flow_run('PF_CURSUS_MAIN');
exec grip_flow.frun('PF_CURSUS_MAIN');
select * from grip_job1_v;

Middels onderstaande aanroep kan een user andermans flow opstarten:
exec grip_flow.fruna('PF_CURSUS_MAIN','GRIP');
Staat een flow in de error en wil men hem opruimen, kan dat als volgt:
exec grip_flow.flow_drop('PF_CURSUS_MAIN');
Logging en debug informatie
Zoals nu wel duidelijk is, worden er op 3 plekken gelogd:
- Grip_audit
- Grip_log -> Grip_log_hist
- Grip_debug -> Grip_debug_hist
Om de tabellen klein te houden, maar toch blijven beschikken over historische gegevens, wordt bij het beëindigen van iedere flow de log-data verplaatst naar de hist-variant, behalve voor grip_audit.
Verder wordt de data van de jobs opgeslagen in tabel grip_job. Indien er een flow gestart wordt, wordt de content van de FLOW geplaatst in grip_job_run met een aantal geresette processattributen. Zodra de flow klaar is, wordt de data van de flow verwijderd uit grip_job_run en toegevoegd aan grip_job_run_hist.
Grip_job -> Grip_job_run -> Grip_job_run_hist
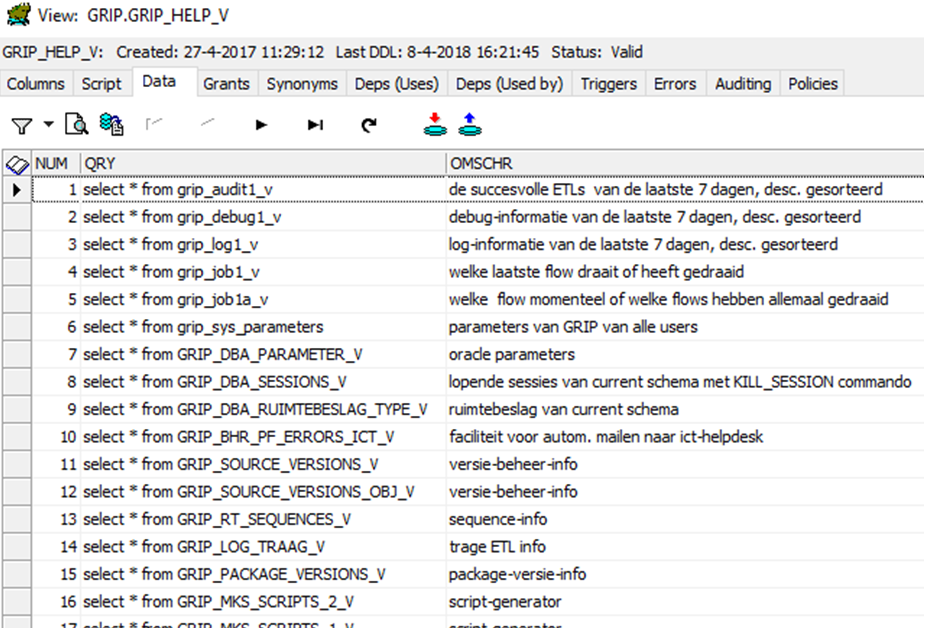
View grip_help_v voor een snel overzicht van welke views er allemaal bestaan.
select * from grip_help_v;
Specials
Er zijn heel veel speciale functies die de ontwikkelaar echt ondersteunen kan. In deze sectie worden een paar specials getoond. Grip bestaat uit een aantal packages waarvan de GRIP_FLOW en GRIP_ETL de belangrijksten zijn. Hieronder worden een paar specials genoemd … om een beeld te krijgen. In een vervolgcursus komen ze allemaal aan bod.
select grip_rac.grip_packages_list from dual;
levert :
GRIP_ETL,GRIP_TAPI,GRIP_BHR,GRIP_PATO,GRIP_NEW,GRIP_UTILS,GRIP_MAIL, GRIP_LIB,GRIP_CSV,GRIP_FLOW,GRIP_HLP,GRIP_RAC,GRIP_VRS,GRIP_AUX
select grip_rac.versionfrom dual;
select grip_rac.str_racnr_user('GRIP')from dual;
select grip_rac.who_is_grip from dual;
select grip_rac.fexec (' select sysdate from dual ') fexec from dual;
select grip_csv.texter('GRIP_JOB', x.rowid,'FREEZE') txter, x.* from GRIP_JOB x;
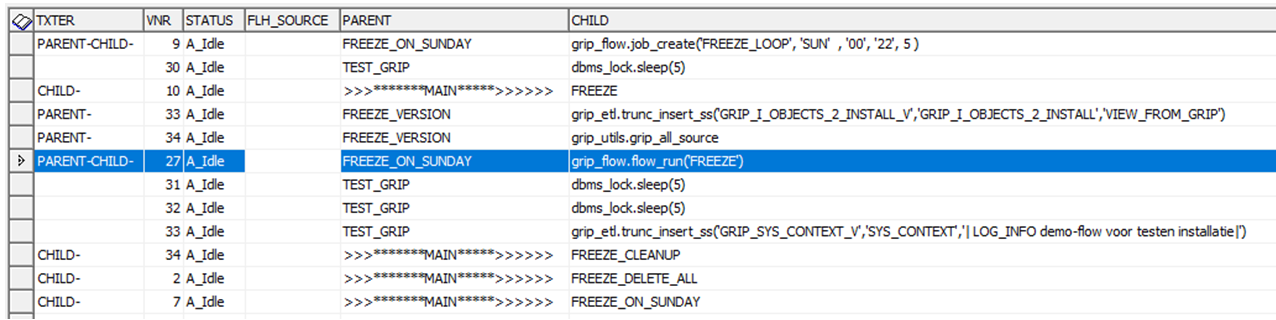
select grip_csv.SqlGetTokenValue('| MERGE_KEYS K1,k2,k3 | SOURCE SOURCE_NAME | BOE |','SOURCE')from dual;
Deze special is een special ETL : de bron is een view, de target is een bijlage van de data van de view in csv, via de mail. Delimeter is het pipe-teken,
grip_csv.query_2_file('STG_PROPBUT_SRE_YARDI_PIV_V','STG_PROPBUT_SRE_YARDI_PIV_V.csv'
,'| SUBJECT bestand voor activa-parameters yardi |
| MAIL BEHEER_1 | | EERSTE_REGELS ONETOMANYS | | DIR SRE_DWH_IN | | DELIMETER pipe |');
Instellen GRIP parameters
Ieder systeem heeft wel variabelen nodig voor vast houden van waarden. Er zijn locale en globale variabelen: middels tabel grip_sys_parameters kunnen variabelen gecreëerd worden. De grip-variabele is bijzonder: per variabele zijn er 4 variabelen per type number,date,char en raw …
De variabelen kun je per view uitvragen en kun je per flow setten of voor het hele schema/datawarehouse .
begin
grip_utils.check_label ('PF_CURSUS_VARIABELE','Aanmaak van de variabele');
grip_utils.set_char ('PF_CURSUS_VARIABELE','test123');
grip_utils.set_num ('PF_CURSUS_VARIABELE',123);
grip_utils.set_date ('PF_CURSUS_VARIABELE',sysdate);
grip_utils.remove_label ('PF_CURSUS_VARIABELE');
--grip_utils.get_raw ('PF_CURSUS_VARIABELE');
--grip_bhr.exec_from_param('PF_CURSUS_VARIABELE');
end;
/
begin
grip_utils.check_label ('PF_CURSUS_VARIABELE' ,'Aanmaak van de variabele','BUURMAN');
grip_utils.set_char ('PF_CURSUS_VARIABELE' ,'test123','BUURMAN');
grip_utils.set_num ('PF_CURSUS_VARIABELE' ,123,'BUURMAN');
grip_utils.set_date ('PF_CURSUS_VARIABELE' ,sysdate,'BUURMAN');
grip_utils.remove_label ('PF_CURSUS_VARIABELE' ,'BUURMAN');
--grip_utils.get_raw ('PF_CURSUS_VARIABELE','BUURMAN');
--grip_bhr.exec_from_param('PF_CURSUS_VARIABELE','BUURMAN');
end;
/
select
grip_utils.get_char ('PF_CURSUS_VARIABELE')
,grip_utils.get_num ('PF_CURSUS_VARIABELE')
,grip_utils.get_date ('PF_CURSUS_VARIABELE')
,grip_utils.get_raw ('PF_CURSUS_VARIABELE')
from dual;
Datamart
In het volgende stuk wordt een datamart gebouwd. Wanneer je stap voor stap onderstaande code uitvoert en kijkt in de logging, zul je merken dat je alle bovenstaande theorie toepast en ieder warehousezinvol zijn kan !
exec grip_etl.trunc_insert_ss_2('GRIP_DEMO_DATA_V','MY_DEMO_DATA_1','| LOG_INFO …|');
Aanmaak van de dimensie-views
create or replace view MY_PERSOON_V
as
select distinct persoon from MY_DEMO_DATA_1;
create or replace view MY_WOONPLAATS_V
as
select distinct WOONPLAATS from (
select WOONPLAATS from MY_DEMO_DATA_1
union
select WOONPLAATS_N from MY_DEMO_DATA_1
);
create or replace view MY_FUNCTIE_V
as
select distinct FUNCTIE from(
select FUNCTIE from MY_DEMO_DATA_1
union
select FUNCTIE_N from MY_DEMO_DATA_1
);
create or replace view MY_BEDRIJF_V
as
select distinct BEDRIJF from (
select BEDRIJF from MY_DEMO_DATA_1
union
select BEDRIJF_N from MY_DEMO_DATA_1
);
create or replace view MY_PROVINCIE_V
as
select distinct PROVINCIE from MY_DEMO_DATA_1;
Aanmaak van de dimensies
begin
grip_etl.actualize_t1('MY_PERSOON_V' ,'MY_PERSOON' ,'| MERGE_KEYS PERSOON |');
grip_etl.actualize_t1('MY_WOONPLAATS_V' ,'MY_WOONPLAATS' ,'| MERGE_KEYS WOONPLAATS |');
grip_etl.actualize_t1('MY_FUNCTIE_V' ,'MY_FUNCTIE' ,'| MERGE_KEYS FUNCTIE |');
grip_etl.actualize_t1('MY_BEDRIJF_V' ,'MY_BEDRIJF' ,'| MERGE_KEYS BEDRIJF |');
grip_etl.actualize_t1('MY_PROVINCIE_V' ,'MY_PROVINCIE' ,'| MERGE_KEYS PROVINCIE |');
end;
/
Aanmaak van de factviews
De eerste view is data voor simuleren voor een initiele situatie, de tweede view geeft persoons-data
voor na een verhuizing.
create or replace view MY_DEMO_FACT_V
as
select persoon
,(select id from MY_PERSOON a where a.persoon = x.persoon ) my_persoon_id
,(select id from MY_WOONPLAATS a where a.woonplaats = x.woonplaats ) my_woonplaats_id
,(select id from MY_FUNCTIE a where a.functie = x.functie ) my_functie_id
,(select id from MY_BEDRIJF a where a.bedrijf = x.bedrijf ) my_bedrijf_id
,(select id from MY_PROVINCIE a where a.provincie = x.provincie ) my_provincie_id
from MY_DEMO_DATA_1 x;
create or replace view MY_DEMO_FACT_N_V
as
select persoon
,(select id from MY_PERSOON a where a.persoon = x.persoon ) my_persoon_id
,(select id from MY_WOONPLAATS a where a.woonplaats = x.woonplaats_n ) my_woonplaats_id
,(select id from MY_FUNCTIE a where a.functie = x.functie_n ) my_functie_id
,(select id from MY_BEDRIJF a where a.bedrijf = x.bedrijf_n ) my_bedrijf_id
,(select id from MY_PROVINCIE a where a.provincie = x.provincie ) my_provincie_id
from MY_DEMO_DATA_1 x;
begin
grip_etl.actualize_t1('MY_DEMO_FACT_V','MY_DEMO_FACT','| MERGE_KEYS my_persoon_id |');
end;
Aanmaak primary-keys dimensies
ALTER TABLE MY_PERSOON ADD CONSTRAINT MY_PERSOON_PK PRIMARY KEY(id);
ALTER TABLE MY_WOONPLAATS ADD CONSTRAINT MY_WOONPLAATS_PK PRIMARY KEY(id);
ALTER TABLE MY_FUNCTIE ADD CONSTRAINT MY_FUNCTIE_PK PRIMARY KEY(id);
ALTER TABLE MY_BEDRIJF ADD CONSTRAINT MY_BEDRIJF_PK PRIMARY KEY(id);
ALTER TABLE MY_PROVINCIE ADD CONSTRAINT MY_PROVINCIE_PK PRIMARY KEY(id);
Aanmaak foreign-keys
ALTER TABLE "MY_DEMO_FACT" add constraint MY_DEMO_FACT_FK1 foreign key (my_persoon_id) references my_persoon (id);
ALTER TABLE "MY_DEMO_FACT" add constraint MY_DEMO_FACT_FK2 foreign key (my_woonplaats_id) references my_woonplaats (id);
ALTER TABLE "MY_DEMO_FACT" add constraint MY_DEMO_FACT_FK3 foreign key (my_functie_id) references my_functie (id);
ALTER TABLE "MY_DEMO_FACT" add constraint MY_DEMO_FACT_FK4 foreign key (my_bedrijf_id) references my_bedrijf (id);
ALTER TABLE "MY_DEMO_FACT" add constraint MY_DEMO_FACT_FK5 foreign key (my_provincie_id) references my_provincie (id);
Aanmaak bitmaps
CREATE BITMAP INDEX MY_DEMO_FACT_IDX1 ON MY_DEMO_FACT (my_persoon_id);
CREATE BITMAP INDEX MY_DEMO_FACT_IDX2 ON MY_DEMO_FACT (my_woonplaats_id);
CREATE BITMAP INDEX MY_DEMO_FACT_IDX3 ON MY_DEMO_FACT (my_functie_id);
CREATE BITMAP INDEX MY_DEMO_FACT_IDX4 ON MY_DEMO_FACT (my_bedrijf_id);
CREATE BITMAP INDEX MY_DEMO_FACT_IDX5 ON MY_DEMO_FACT (my_provincie_id);
Type-1 actualiseren
begin
grip_etl.actualize_t1('MY_DEMO_FACT_V' ,'MY_DEMO_FACT','| MERGE_KEYS my_persoon_id |');
grip_etl.actualize_t1('MY_DEMO_FACT_N_V','MY_DEMO_FACT','| MERGE_KEYS my_persoon_id |');
end;
/
select * from grip_audit1_v;
Type-2 actualiseren
begin
grip_etl.actualize_t2('MY_DEMO_FACT_V','MY_DEMO_FACT','| MERGE_KEYS my_persoon_id |');
grip_etl.actualize_t2('MY_DEMO_FACT_N_V','MY_DEMO_FACT','| MERGE_KEYS my_persoon_id |');
end;
/
select * from grip_audit1_v;
Controleer de data
select * from MY_DEMO_FACT
order by person;
ETL naar de FLOW
begin
grip_etl.cmd('RECORD_ON PF_MY_WAREHOUSE');
--
grip_etl.record_job('PF_MY_WAREHOUSE','PF_DIMENSIES','FLOW');
grip_etl.record_job('PF_MY_WAREHOUSE','PF_FACT','FLOW');
--
grip_etl.cmd('RECORD_OFF');
end;
begin
grip_etl.cmd('RECORD_ON PF_DIMENSIES');
--
grip_etl.actualize_t1('MY_PERSOON_V','MY_PERSOON','| MERGE_KEYS PERSOON |');
grip_etl.actualize_t1('MY_WOONPLAATS_V','MY_WOONPLAATS','| MERGE_KEYS WOONPLAATS |');
grip_etl.actualize_t1('MY_FUNCTIE_V','MY_FUNCTIE','| MERGE_KEYS FUNCTIE |');
grip_etl.actualize_t1('MY_BEDRIJF_V','MY_BEDRIJF','| MERGE_KEYS BEDRIJF |');
grip_etl.actualize_t1('MY_PROVINCIE_V','MY_PROVINCIE','| MERGE_KEYS PROVINCIE |');
--
grip_etl.cmd('RECORD_OFF');
end;
begin
grip_etl.cmd('RECORD_ON PF_FACT');
--
grip_etl.actualize_t2('MY_DEMO_FACT_V','MY_DEMO_FACT','| MERGE_KEYS my_persoon_id |');
--
grip_etl.cmd('RECORD_OFF');
end;
Verversen van het warehouse
exec grip_flow.frun('PF_MY_WAREHOUSE')
select * from grip_audit1_v
Van ster naar plat
Op basis van een datamodel met goede foreignkeys, kan met de functie grip_etl.str_qry een query gegenereerd worden die over alle tabellen gaat waar naar gerefereerd wordt. Op deze wijze kan men heel snel ETL ontwikkelen waarbij het meeste van de view al bestaat. Deze functie is ook handig voor het genereren van Bridge-view op datavault.
select grip_etl.str_qry('MY_DEMO_FACT')from dual;
SELECT
T0.PERSOON PERSOON_0
,'| ' D_0_MY_DEMO_FACT
, T1.BEDRIJF BEDRIJF_1
,'| ' D_1_MY_BEDRIJF
, T2.FUNCTIE FUNCTIE_2
,'| ' D_2_MY_FUNCTIE
, T3.PERSOON PERSOON_3
,'| ' D_3_MY_PERSOON
, T4.PROVINCIE PROVINCIE_4
,'| ' D_4_MY_PROVINCIE
, T5.WOONPLAATS WOONPLAATS_5
,'| ' D_5_MY_WOONPLAATS
FROM
MY_DEMO_FACT T0
,MY_BEDRIJF T1
,MY_FUNCTIE T2
,MY_PERSOON T3
,MY_PROVINCIE T4
,MY_WOONPLAATS T5
WHERE1=1
and T0.MY_BEDRIJF_ID = T1.ID(+)
and T0.MY_FUNCTIE_ID = T2.ID(+)
and T0.MY_PERSOON_ID = T3.ID(+)
and T0.MY_PROVINCIE_ID = T4.ID(+)
and T0.MY_WOONPLAATS_ID = T5.ID(+)
Datavault
Voor datavaultmodelleren met GRIP zijn de 2 ETL-routines beschikbaar:
grip_etl.actualize_link('','','')
grip_etl.actualize_hub ('','','')
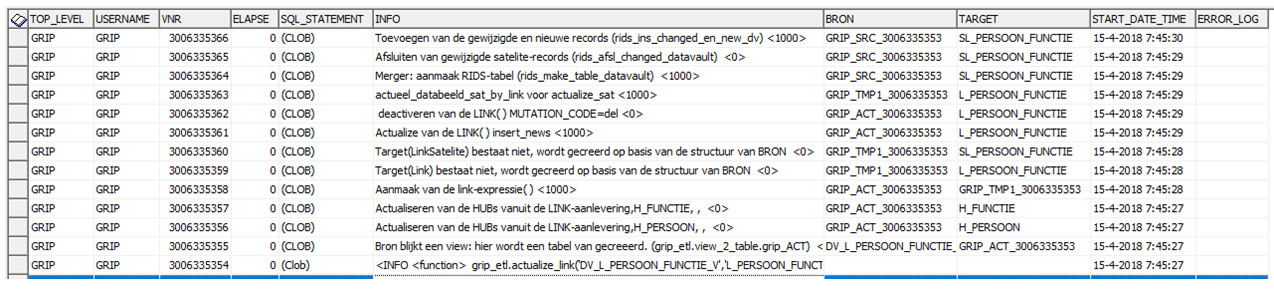
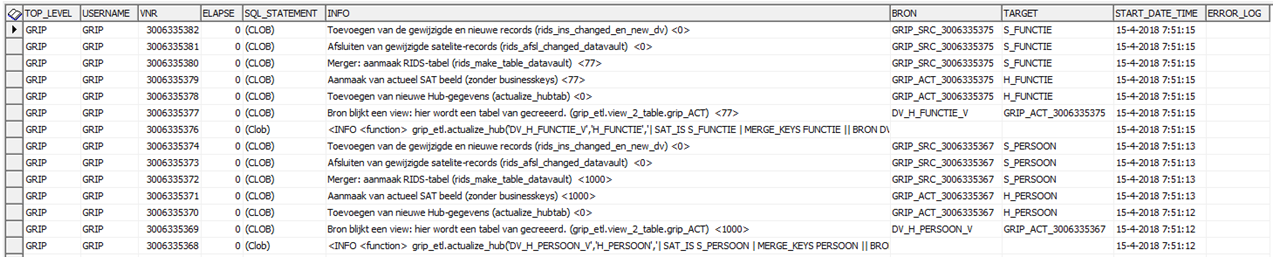
Middels onderstaande wordt duidelijk gemaakt hoe de routines gebruikt moeten worden. In de logging wordt duidelijk uit hoeveel templates deze routines bestaan: de actualize_link bestaat uit wel 12 templates !.
create or replace view dv_h_persoon_v
as
select persoon,sum(1) aantal,'DEMO_BRON' RECORD_SOURCE,sysdate LOAD_DTS
from MY_DEMO_DATA_1
group by persoon;
create or replace view dv_h_functie_v
as
select functie,sum(1) aantal,'DEMO_BRON' RECORD_SOURCE,sysdate LOAD_DTS
from MY_DEMO_DATA_1
group by functie;
exec GRIP_ETL.ACTUALIZE_hub('DV_H_PERSOON_V','H_PERSOON','| SAT_IS S_PERSOON | MERGE_KEYS PERSOON |');
exec GRIP_ETL.ACTUALIZE_hub('DV_H_FUNCTIE_V','H_FUNCTIE','| SAT_IS S_FUNCTIE | MERGE_KEYS FUNCTIE |');
create or replace view dv_l_persoon_functie_v
as
select persoon, functie ,sum(1) aantal,'DEMO_BRON' RECORD_SOURCE,sysdate LOAD_DTS
from MY_DEMO_DATA_1
group by persoon,functie;
exec GRIP_ETL.ACTUALIZE_link('DV_L_PERSOON_FUNCTIE_V','L_PERSOON_FUNCTIE'
,'| HUB_LIST H_PERSOON,H_FUNCTIE | SAT_IS SL_PERSOON_FUNCTIE | ');
select * from grip_log1_v;
Eenvoudig uitbouwen van het datavaultmodel
create or replace view DV_H_WOONPLAATS_V
as
select distinct WOONPLAATS from MY_DEMO_DATA_1;
create or replaceview DV_H_BEDRIJF_V
as
select distinct BEDRIJF from MY_DEMO_DATA_1;
exec GRIP_ETL.ACTUALIZE_hub('DV_H_WOONPLAATS_V','H_WOONPLAATS','| MERGE_KEYS WOONPLAATS |');
exec GRIP_ETL.ACTUALIZE_hub('DV_H_BEDRIJF_V' ,'H_BEDRIJF' ,'| MERGE_KEYS BEDRIJF |');
create or replace view DV_L_FUNCTIE_BEDRIJF_V
as
select distinct functie, BEDRIJF fromMY_DEMO_DATA_1;
exec GRIP_ETL.ACTUALIZE_link('DV_L_FUNCTIE_BEDRIJF_V','L_FUNCTIE_BEDRIJF','| HUB_LIST H_FUNCTIE,H_BEDRIJF |');
Met onderstaande functie wordt een select gegenereerd uit het datavault-datamodel voor bijvoorbeeld een ETL-view voor een Dimensie..
select grip_etl.str_qry('L_FUNCTIE_BEDRIJF') from dual;
SELECT
T0.RECORD_SOURCE RECORD_SOURCE_0
, T0.LOAD_DTS LOAD_DTS_0
, T0.END_LOAD_DTS END_LOAD_DTS_0
,'| ' D_0_L_PERSOON_FUNCTIE
, T1.FUNCTIE FUNCTIE_1
, T1.RECORD_SOURCE RECORD_SOURCE_1
, T1.LOAD_DTS LOAD_DTS_1
, T1.END_LOAD_DTS END_LOAD_DTS_1
,'| ' D_1_H_FUNCTIE
, T2.PERSOON PERSOON_2
, T2.RECORD_SOURCE RECORD_SOURCE_2
, T2.LOAD_DTS LOAD_DTS_2
, T2.END_LOAD_DTS END_LOAD_DTS_2
,'| ' D_2_H_PERSOON
FROM
L_PERSOON_FUNCTIE T0
,H_FUNCTIE T1
,H_PERSOON T2
WHERE 1=1
and T0.H_FUNCTIE_ID = T1.ID(+)
and T0.H_PERSOON_ID = T2.ID(+)
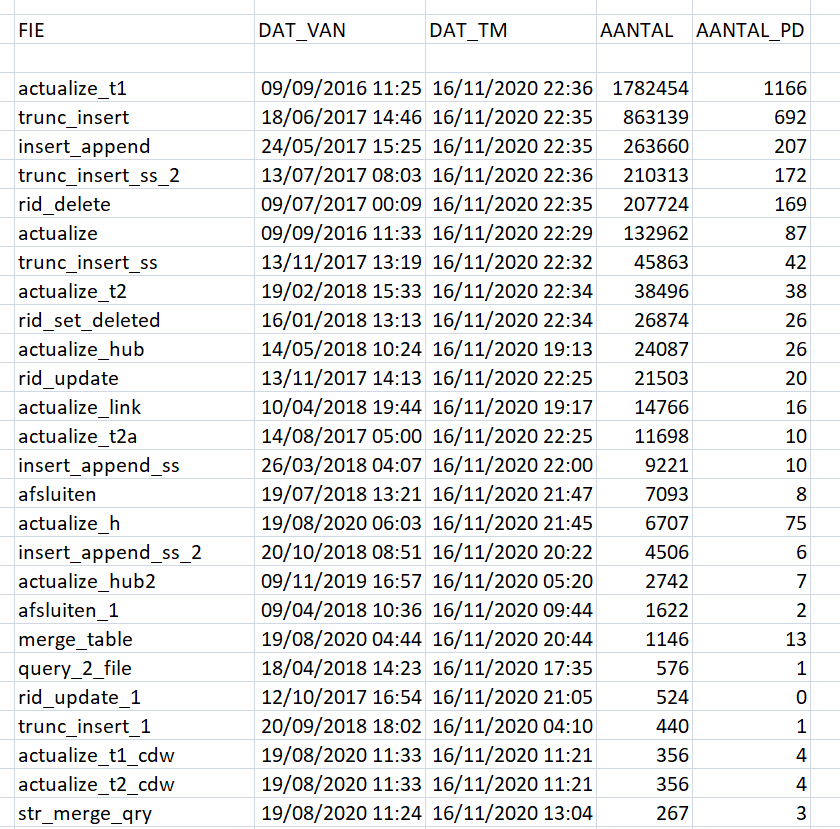
Tot slot hieronder een overzicht van de 3 productieomgevingen van schiphol. De figuur geeft het GRIP_ETL-functiegebruik weer.